








我看网上都是一个版本的中文文档,有些地方细节不够清楚,我这里补充一下。
首先flink在1.9才开始支持支持python的。开发主要思路是要先把源码编译成python的依赖包,然后用pip命令把包集成到python库。
安装命令如下:
1.git clone https://github.com/apache/flink.git
2.git fetch origin release-1.9 && git checkout -b release-1.9 origin/release-1.9
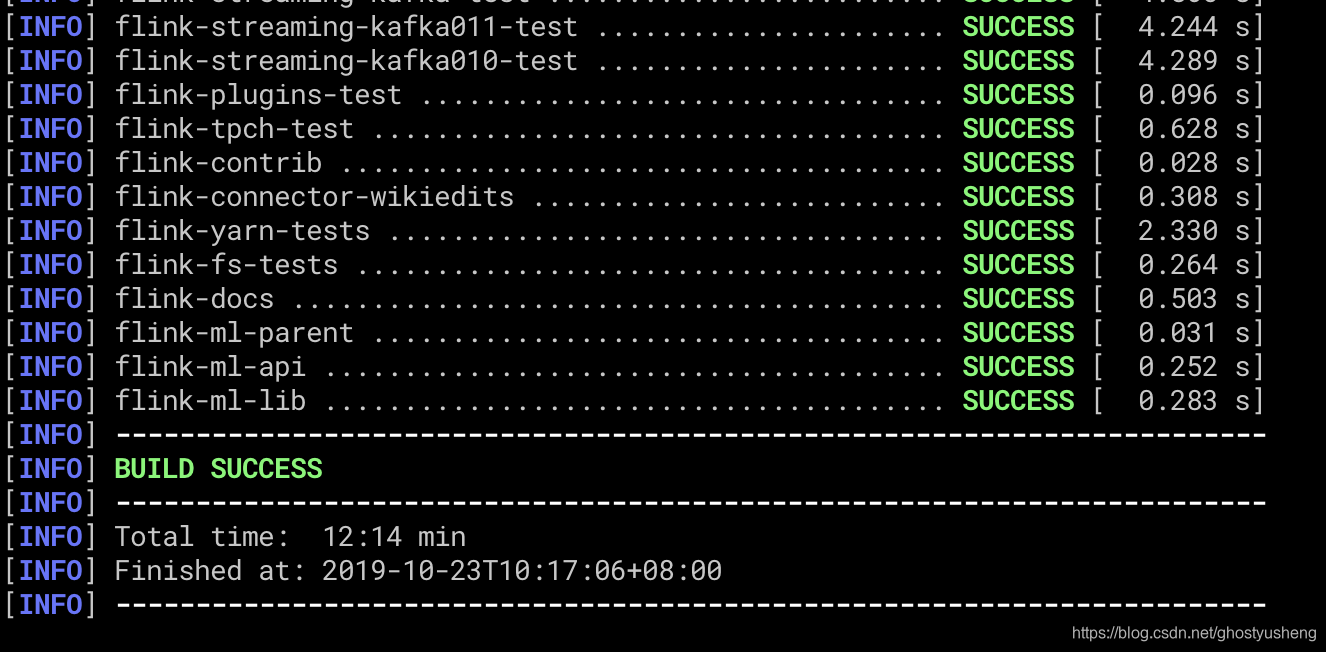
3.mvn clean install -DskipTests -Dfast
显示build success代表成功,如果你没装java1.8环境是build不起来的,貌似还需要node npm环境。
4.cd flink/flink-python; python3 setup.py sdist bdist_wheel (git目录下有个flink-python目录)
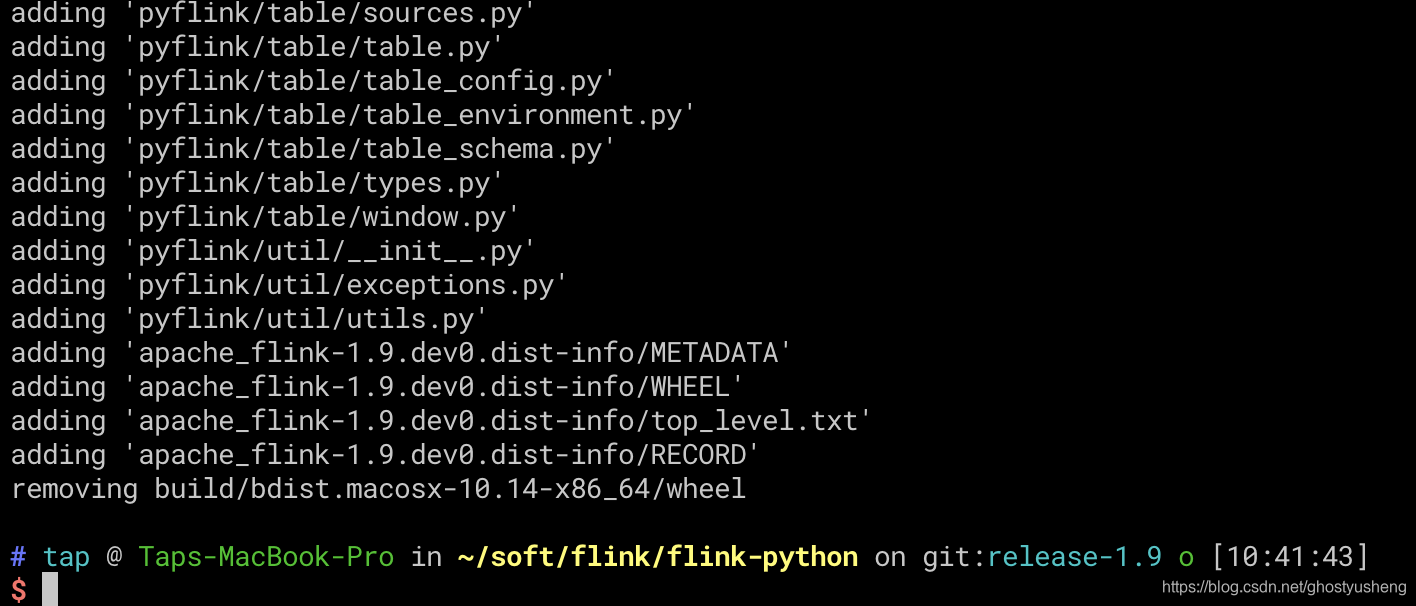 5.
5.
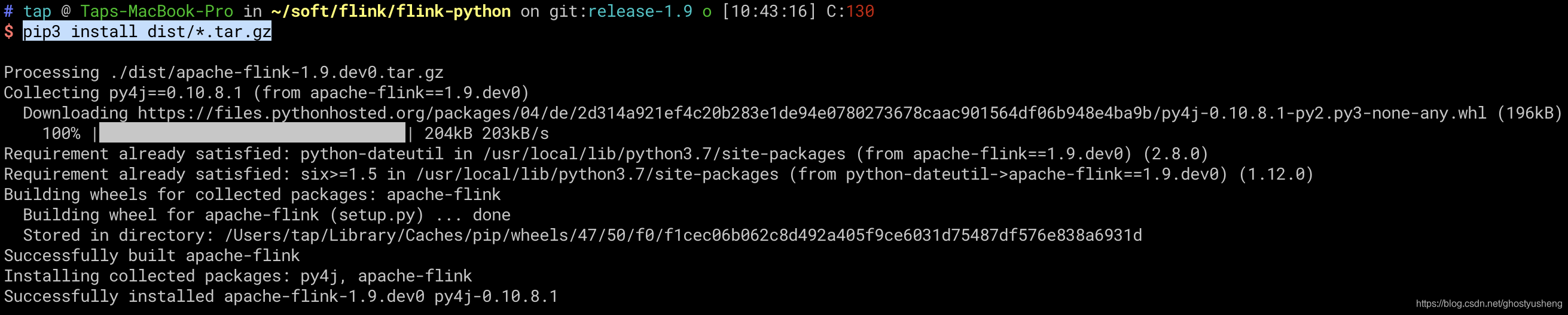
建议使用python3环境安装
pip3 install dist/*.tar.gz
6.
检查一下python依赖包是否安装上了
pip3 list|grep dev
 关于如何使用这个包
关于如何使用这个包
官方文档地址: https://ci.apache.org/projects/flink/flink-docs-release-1.9/api/python/
单节点集群的部署
在上面步骤我们给python打上了pyflink1.9的依赖包,但是flink集群我们还没有部署。以下是部署步骤
wget https://archive.apache.org/dist/flink/flink-1.9.0/flink-1.9.0-bin-scala_2.12.tgz
tar xvf flink-1.9.0-bin-scala_2.12.tgz
cd flink-1.9.0/bin
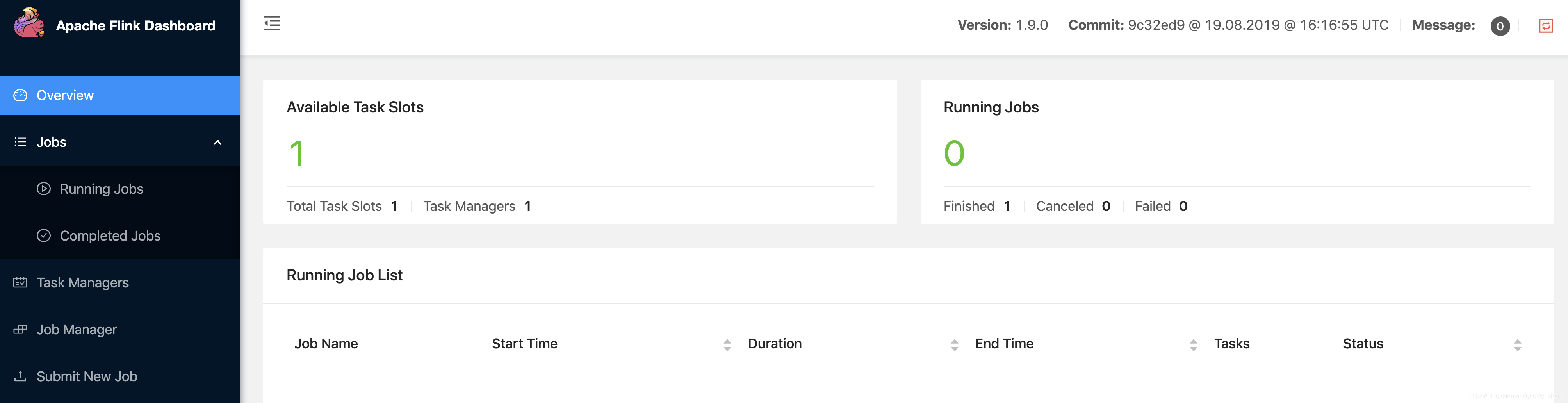
./start-cluster.sh
访问localhost:8081
使用DEMO
flink程序默认可以在本地起一个迷你集群运行,当然你也可以使用你部署的flink集群来执行这个脚本。
flink.py程序:
from pyflink.dataset import ExecutionEnvironment
from pyflink.table import TableConfig, DataTypes, BatchTableEnvironment
from pyflink.table.descriptors import Schema, OldCsv, FileSystem
exec_env = ExecutionEnvironment.get_execution_environment()
exec_env.set_parallelism(1)
t_config = TableConfig()
t_env = BatchTableEnvironment.create(exec_env, t_config)
t_env.connect(FileSystem().path('/tmp/input')) \
.with_format(OldCsv()
.line_delimiter(' ')
.field('word', DataTypes.STRING())) \
.with_schema(Schema()
.field('word', DataTypes.STRING())) \
.register_table_source('mySource')
t_env.connect(FileSystem().path('/tmp/output')) \
.with_format(OldCsv()
.field_delimiter('\t')
.field('word', DataTypes.STRING())
.field('count', DataTypes.BIGINT())) \
.with_schema(Schema()
.field('word', DataTypes.STRING())
.field('count', DataTypes.BIGINT())) \
.register_table_sink('mySink')
t_env.scan('mySource') \
.group_by('word') \
.select('word, count(1)') \
.insert_into('mySink')
t_env.execute("python_job")
(1) 迷你集群使用方法,python3 flink.py
(2) 使用上述搭建好的集群使用方法, cd flink-1.9.0/bin && ./flink run -py ~/demo/flink.py
执行成功可以看到:

异常处理
local class incompatible
那大概是你下载错误了flink的版本,造成python flink版本和flink自身的版本对不上,上述教程都是1.9的。
还有种可能性就是,flink可执行文件要用 wget https://archive.apache.org/dist/flink/flink-1.9.0/flink-1.9.0-bin-scala_2.12.tgz包里的,不要用之前git克隆的flink可执行文件。
处理kafka实例化报错
如果你是按照上面教程,你会发现pyflink.table.descriptors import Kafka 中的 Kafka()实例化会失败,然而官方也没有给出解决方案,根据不断的尝试摸索,正确的做法是,flink/flink-connectors/flink-connector-kafka-base/target里面的flink-connector-kafka-base_2.11-1.9-SNAPSHOT.jar + original-flink-connector-kafka-base_2.11-1.9-SNAPSHOT.jar JAR包复制到flink/flink-python/dist/apache-flink-1.9.dev0/deps/lib目录,让后使用tar czvf命令重新打包成pyflink依赖包,把之前的卸载掉pip3 uninstall apache-flink && pipi3 install 新打包.tar.gz.
— 补充: 实例化elasticsearch组件报错也是同理。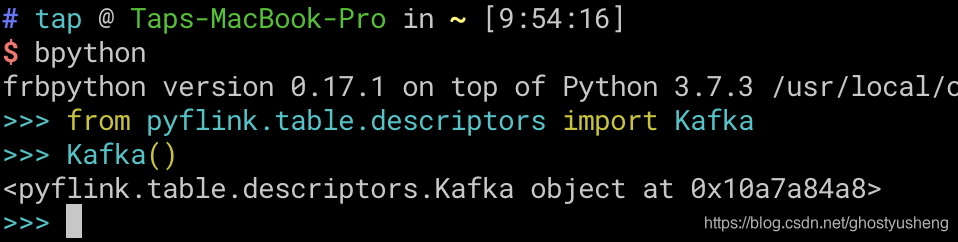
– 补充2: 引用qinhan1219
处理kafka实例化报错这一步 你是将flink-connector-kafka-base_2.11-1.9-SNAPSHOT.jar + original-flink-connector-kafka-base_2.11-1.9-SNAPSHOT.jar复制到flink/flink-python/dist/apache-flink-1.9.dev0/deps/lib目录,这一步确实实例化Kafka()的时候不会报错,但是后面编程时候会有很大问题 正确做法将 flink-json-1.10.0-sql-jar.jar flink-sql-connector-kafka_2.11-1.10.0.jar kafka-clients-2.2.0.jar flink-jdbc_2.11-1.10.0.jar这几个包复制到site-packages/pyflink/lib下就可以了 我的是/home/yy1s/project/test/lib/python3.6/site-packages/pyflink/lib /home/yy1s/project/test/lib/python3.6/site-packages/pyflink/lib [yy1s@hub lib]$ ls -lrt total 154404 -rw-rw-r–. 1 yy1s yy1s 9931 Sep 2 2019 slf4j-log4j12-1.7.15.jar -rw-rw-r–. 1 yy1s yy1s 489884 Sep 2 2019 log4j-1.2.17.jar -rw-rw-r–. 1 yy1s yy1s 19301237 Feb 7 13:54 flink-table_2.11-1.10.0.jar -rw-rw-r–. 1 yy1s yy1s 22520058 Feb 7 13:54 flink-table-blink_2.11-1.10.0.jar -rw-rw-r–. 1 yy1s yy1s 110055308 Feb 7 13:54 flink-dist_2.11-1.10.0.jar -rw-r–r--. 1 yy1s yy1s 89695 Feb 7 14:51 flink-jdbc_2.11-1.10.0.jar
补充
- java最好用"1.8.0_131"版本,不然很有可能会报错.官方要求是8u51以上。
yum install gcc gcc-c++ -y依赖库记得装.- NVM装个node最新版,不然有的模块可能编译失败
总结
我个人最后是都装好了,但是苦于pyflink社区资料太少,本身java底子也不好,加上官方python文档教程太少,经常要对照java的类猜参数,本身对流计算经验甚少,转向scala了。对自己技术有信心的小伙伴可以尝试。














 2658
2658











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









