图像分类中的max pooling和average pooling是对特征的什么来操作的,结果是什么?
19 个回答


什么是池化
池化(Pooling)操作十分常见于基于 CNN 的图像分类网络。这一操作本身非常简单,如下图所示,是两种池化操作:平均池化和最大池化,其 kernel size 和 stride 均为 2。这里的 kernel size 为 2,指的是我们使用 2×2 的一小块图像计算结果中的一个像素;而 stride 为 2,则表示用于计算的图像块,每次移动 2 个像素以计算下一个位置。

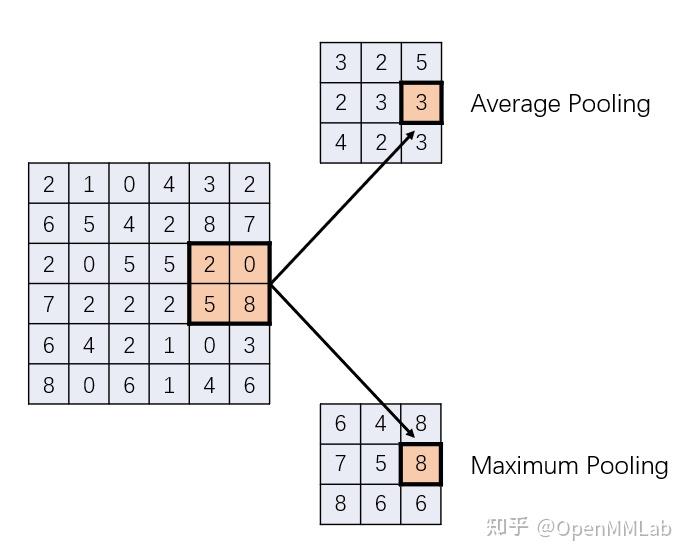
平均池化(Average Pooling)和最大池化(Maximum Pooling)的概念就更好理解了,它们指的是如何利用图像块计算结果,取平均值就是平均池化,取最大值就是最大池化。当然,如果你愿意,也可以取最小值,搞出个最小池化、取中值,搞出个中值池化。
池化的作用
说了这么多,那么池化到底有什么用呢?为什么要搞出不同的池化方式?其实池化本质上就是缩小特征图,从而降低网络中特征图的大小,因此在一些地方,也会以下采样/降采样来指代池化。
缩小特征图一个显而易见的好处是降低了计算量,特征图小了,卷积遍历整张特征图需要的计算也就少了。但这其实不是池化最重要的目的。池化最重要的一个作用是扩大神经元,也就是特征图中一个像素的感受野大小。
在浅层卷积中,特征图还很大,一个像素能接收到的实际图像面积很小。虽然逐层的卷积一定程度上能够沟通相邻的神经元,但作用有限。而池化,通过简单粗暴地合并相邻的若干个神经元,使缩小后的特征图上的神经元能够获得来自原图像更大范围的信息,从而提取出更高阶的特征。
而平均池化和最大池化分别代表了合并相邻神经元信息的两种策略。平均池化能够更好地保留所有神经元的信息,能够体现出对应区域的平均响应情况。而最大池化则能够保留细节,保留对应区域的最大响应,防止强烈的响应被周围的神经元弱化。
最后,希望大家可以多多关注 MMClassification,我们紧跟时代热潮,支持目前大部分主流的主干网络和分类算法;同时 OpenMMLab 包含了视觉领域绝大部分的方向的算法库,欢迎大家关注呀。

恰好做过这方面的研究,我来回答一下吧~
题主问的应该是feature coding之后的那步pooling(bag-of-words framework下),而上面回答的那个pooling用在CNN中(CNN和BoW是两套系统),两个不太一样。CNN的那个pooling主要目的是降维,也是CNN精髓所在。但是我们特征编码之后做pooling,是因为不做就进行不下去了。
这个故事还要从feature coding讲起。最初编码的方式比较耿直(VQ,矢量量化),这样计算的结果本身是一个统计直方图,也就是向量的,因此不需要做什么处理,直接送到SVM里面就完了。但是由于特征本身语义不高,这样的编码方式会造成比较大的误差。2009年,图像方面的稀疏编码被提了出来(Jianchao Yang, Kai Yu, Yihong Gong, and Thomas Huang.
Linear spatial pyramid matching using sparse coding for image classification. CVPR2009.)掀起了一股特征编码的潮流(集中在09-10这个阶段)。稀疏编码减小了量化误差,效果也十分显著(14%的正确率提升),但是经过稀疏编码得到的结果是一个矩阵而不是向量(具体可以看paper),矩阵的两个维度分别是word和location,这个矩阵是无法直接拿来分类的,所以需要对它做pooling变成一个向量,这就是题主所说的pooling。
刚开始的pooling比较拍脑袋,sum就是对每一列求和,max就是求最大,因为矩阵里面的数值强度表现了这个词本身的响应,所以对响应不同的操作会得到不同的结果。上面的那篇文章也比较了一些pooling的效果,但是没有探讨哪种比较好,或者哪种为什么好。
后来有一些工作开始思考什么样的pooling比较好以及为什么好。比如Y. Boureau, J. Ponce, Y. LeCun A Theoretical Analysis of Feature Pooling in Visual Recognition, ICML, 2010,P. Koniusz, F. Yan, K. Mikolajczyk Comparison of Mid-Level Feature Coding Approaches And Pooling Strategies in Visual Concept Detection. CVIU, 117(5):479-492, 2013。 CVIU的这篇文章提出了AxMin的方法,应该是比较新的(是不是最新不太确定)。也有尝试探讨什么样的pooling好以及为什么好的:Protected Pooling Method Of Sparse Coding In Visual Classi cation,ICCVG,2014(会很水而且写得非常naive,只供参考)。不过pooling本身对分类系统的影响不大,2%以内差不多。
总的来说pooling确实起到了整合特征的作用,因为不同的方法得到的结果有些差别,不过我理解主要动机还是“不池化就没法继续了”这种感觉。或许有不对的地方,希望对题主有帮助~