晓强的Python日常-Requests库网络爬虫实战2
本文将讲解百度/360搜索关键字的提交和IP地址归属地的自动查询
实例③:百度搜索关键字的提交
搜索引擎都会对关键词的搜索提供一个接口
对python的requests库来说只需要构造这样的一个url,就可以实现对关键词的提取。

完整代码如下:附注释:
# -*- coding: utf-8 -*-
import requests
keyword = 'Python'
#以查询关键字Python为例
try: #基本框架
kv = {'wd':keyword}
#创建一个键值对
r = requests.get("http://www.baidu.com/s",params = kv)
#kv赋值给params
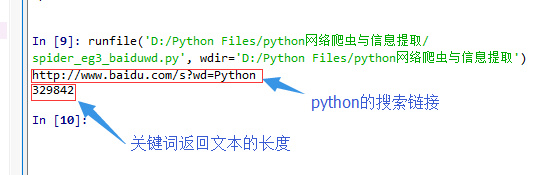
print(r.request.url)
#打印一下Python的搜索网址
r.raise_for_status
print(len(r.text))
#返回内容太多会导致idle失效,所以检测返回数据的时候尽量约束一个范围空间,
#比如r.text[-500:]只查看后500个字节
except:
print("爬取失败")
程序的运行结果
实例⑤:IP地址的自动查询:
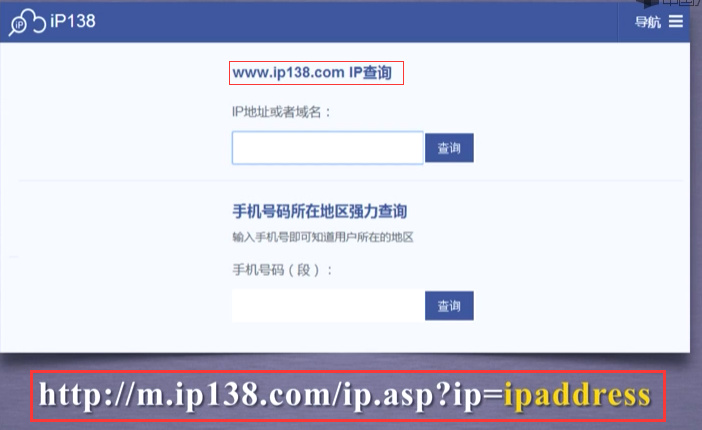
在网上找一个IP地址的库,这里以IP138提供的IP地址库为例
完整代码:
# -*- coding: utf-8 -*-
import requests
url = "http://m.ip138.com/ip.asp?ip = "
try:
r = requests.get(url + '202.199.224.19')
r.raise_for_status
r.encoding = r.apparent_encoding
print(r.text[-500:])
except:
print("爬取失败")



