







一、目的
一个搜索引擎使用的时候必定需要排序这个模块,一般情况下在不选择按照某一字段排序的情况下,都是按照打分的高低进行一个默认排序的,所以如果正式使用的话,必须对默认排序的打分策略有一个详细的了解才可以,否则被问起来为什么这个在前面,那个在后面不好办,因此对Elasticsearch的打分策略详细的看了下,虽然说还不是了解的很全部,但是大部分都看的差不多了,结合理论以及搜索的结果,做一个简单的介绍
二、Elasticsearch的打分公式
Elasticsearch的默认打分公式是lucene的打分公式,主要分为两部分的计算,一部分是计算query部分的得分,另一部分是计算field部分的得分,下面给出ES官网给出的打分公式:
score(q,d) =
queryNorm(q)
· coord(q,d)
· ∑ (
tf(t in d)
· idf(t)²
· t.getBoost()
· norm(t,d)
) (t in q) queryNorm(q):
对查询进行一个归一化,不影响排序,因为对于同一个查询这个值是相同的,但是对term于ES来说,必须在分片是1的时候才不影响排序,否则的话,还是会有一些细小的区别,有几个分片就会有几个不同的queryNorm值
queryNorm(q)=1 / √sumOfSquaredWeights
上述公式是ES官网的公式,这是在默认query boost为1,并且在默认term boost为1 的情况下的打分,其中
sumOfSquaredWeights =idf(t1)*idf(t1)+idf(t2)*idf(t2)+...+idf(tn)*idf(tn)
其中n为在query里面切成term的个数,但是上面全部是在默认为1的情况下的计算,实际上的计算公式如下所示:
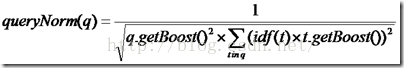
coord(q,d):
coord(q,d)是一个协调因子它的值如下:
coord(q,d)=overlap/maxoverlaptf(t in d):
即term t在文档中出现的个数,它的计算公式官网给出的是:
tf(t in d) = √frequencyidf(t):
这个的意思是出现的逆词频数,即召回的文档在总文档中出现过多少次,这个的计算在ES中与lucene中有些区别,只有在分片数为1的情况下,与lucene的计算是一致的,如果不唯一,那么每一个分片都有一个不同的idf的值,它的计算方式如下所示:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 3018
3018











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









