如何解读「量子计算应对大数据挑战:中国科大首次实现量子机器学习算法」?
11 个回答

谢邀。
每个量子计算的大新闻都邀我,但我的主业真的是机器学习..
简单讲一讲吧。
1)关于这项工作本身
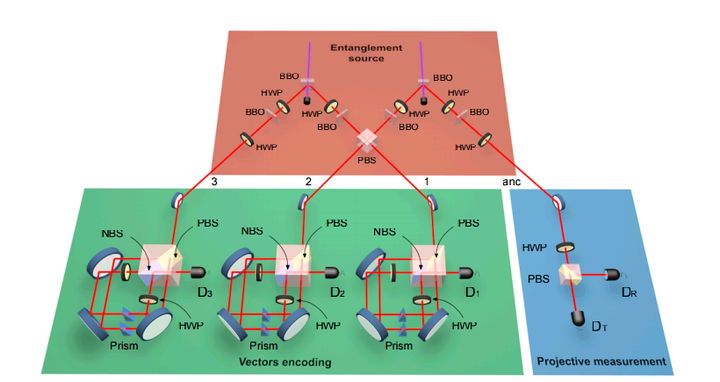

简单来说就是,用光子比特(photonic qubit)作为量子比特,用透镜构成量子逻辑门,整体是一台光量子计算机。
量子光学这套东西,潘教授已经玩得出神入化,几乎甩开其他所有学校了。
取得的成就是用量子计算正确地运行了机器学习算法。
但题目里【首次实现量子机器学习算法】的说法可能不太准确。
我猜是因为没有把Dwave算作真正的量子计算机,因为Dwave只能运行量子退火算法。而潘教授研究的这种光量子计算机是通用型的“标准”量子计算机。通用型量子计算机是可以运行所有量子算法的,这就是厉害的地方吧。
这项工作的意义就是在于通用型量子计算机第一次成功的运行了量子机器学习算法。
之前大家也都知道这个方案肯定可行,但是实验难度很大。
2)未来的障碍
通用机这么好,为什么大家不发展通用型量子计算机呢?
没有别的原因,就是因为太难了。
五十年前大家觉得可控核聚变还有五十年,现在大家觉得可能还要五十年...
通用型量子计算机不会比这难度小。
这篇文章里的量子计算机非常初级,只能处理最简单的问题。而且可扩展性很差,按着这种搭光路的方法,可能第一台有实用价值的通用型量子计算机比埃尼阿克还要笨重。
世界上第一台电子计算机ENIAC长30.48米,宽1米,高2.4米,占地面积约170平方米,30个操作台,重达30英吨,耗电量150千瓦,造价48万美元。
甚至这种思路可能没有结果。比特数一高,光路就复杂到再也无法在实验室搭出来。
当然集成光学等学科的发展也可能让光量子计算机有所突破。一切都是未知数。
通用型量子计算机还有其他思路,基于核磁共振、基于超导环等等。
但暂时还看不出来到底哪条路是对的,所以每一路都养着一大批物理PhD在研究。
光量子计算机这条路也只是诸多候选方案之一。有没有光明的未来只有不断尝试才知道。
之前评论区里总有人问我,为什么中国不发展量子计算机?
这里就顺便回答一下。量子计算这么重要的东西中国不可能没有发展。但有的东西不是我们想有就能有的。通用型量子计算机什么时候才能有重大突破谁也说不好。现在的每一小步可能都踏在错误的方向上,但是每一小步也都有可能变成真正的一大步。
3)补充一些背景故事
在我本科毕业时,都未曾听说过潘教授的组开始量子机器学习的研究。去年年底的时候,听某位USTC师姐说道,潘组已经开始研究量子机器学习。现在这个应该是初步成果了。
本科班上也有同学保研到潘教授组,没记错的话都是专业前几的。大多数本科就参与组内科研的大神。
有这么厉害的导师,又有这么优秀的学生,还有多到让人吓一跳的经费,可以发射世界上第一颗量子卫星,现在再达成【首次实现量子机器学习算法】的成就也不让人意外了。
量子机器学习/量子人工智能最近两年在飞速发展。
首先是,CIA,没错就是大家熟知的那个美国中央情报局,作为大股东资助的Dwave公司开发出Dwave量子计算机。
然后,2013年,美国国家航空航天局NASA和Google联合成立了量子人工智能(Quantum AI Lab)。
去年下半年,又发现洛克马丁,嗯,就是那个开发了F16/F117/F22的公司,与牛津大学联合建立了量子优化和机器学习研究中心。
不要问我美帝想干什么,我真的不知道。。
作为此领域的一员表示,欢迎各国争先恐后地为人类的未来砸钱。
再来一点题外话。
牛津大学真心是一所有独特气质的学校。CS系竟然有一个大组叫Quantum Group。是CS系规模最大的方向之一。专门研究量子物理和计算机交叉的方向,进行各种科幻研究。。不愧是英语世界无数大学的母本。
剑桥大学、哈佛大学是牛津一脉相承。
东京大学也是以牛津为模板建立的亚洲第一所现代大学。
希望牛津可以继续保持这种传承了八百年气质吧。全世界的大学都变成一个样就太无聊了。
再补充一个背景。
量子机器学习(Quantum Machine Learning)就是量子计算+机器学习么?
不是的。
量子机器学习还包括另外一部分,就是用量子力学的思想和模型来改进机器学习算法。
【
A Quantum-Theoretic Approach to Distributional Semantics】
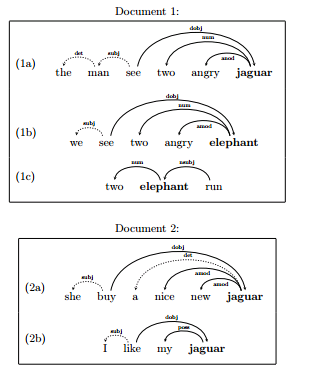
比如说这篇很有名的NLP相关的文章。用密度矩阵表示单词在文本中的信息。词汇相似度用Trace(MN)表示,即两个密度矩阵乘积的迹来表示。为什么要用密度矩阵?因为密度矩阵包含了一个量子系统的所有信息,而我们又可以把一个文本抽象为量子系统。
文本是这样的。
量子模型是这样的。
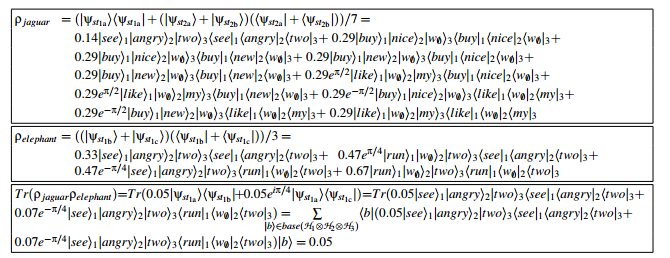

jaguar和elephant两个单词在此文本里的相似度是0.05。
这个量子模型的最终效果也胜过现有模型。感兴趣可以自己读读看。
这种思路对机器学习的促进是不受量子计算机发展的限制的,可以直接在电子计算机上运行。
实际上,我导师也一直鼓励我多尝试这个思路。因为除了成果可以直接用,不用等不知道哪天才出现的量子计算机。
boss第一次发这个领域的顶会是在2009年。他吐槽那个时候那群计算机出身的审稿人根本看不懂量子力学在机器学习里的意义,一篇文章改了快半年才通过。后来情况就好多,大概有3,4篇量子机器学习在ML/AI/NLP的顶会被顺利接受。
然后最近几年,CS出身的科学家发表量子机器学习的文章也越来越多,几乎占了半壁江山的感觉。
这大概就是现在的形势了。
这些背景故事告诉了我们,美帝军方水很深,量子机器学习的世界还很广阔。
暂且如此。
以上。

这是2015年发表在 PRL 上的一个实验文章,这篇文章以及量子机器学习的算法我都亲自读过,所以来谈谈这文章的内容。
量子机器学习做的事情并不是很难理解,下面我用最最易懂的语言来描述一下这个工作做的是什么。
以下关于机器学习的说法来自于我读到的算法物理理论文章,作为一个非计算机专业的人,对机器学习的概念什么肯定写得很不准确,求计算机大神轻喷。
其实机器学习就是让计算机实现自动对信息分类处理等操作的过程。通常来说,首先我们要做的是对我们所得的信息利用一种量化方式,将这些信息抽象成向量,然后通过比较各向量间的距离来对信息进行分类。这个第一步,将信息搞成向量,不是这个文章做的事情,这个文章实现的是对两个向量间距离的计算。
从算法上来讲,最简单的情形,我们需要求的是这样一个问题: 现在我有一个由好多好多向量组成的一簇向量,以及一个待归类的向量v,那么,这个v和那(一簇向量的平均值)之间的距离是多少?这个问题从算法本身来讲只要引入一个类似于标签作用的辅助'比特'(之所以用引号,因为这个比特不是一位二进制数),采取合适的量子编码编出一个量子态,最后对编码后量子态中的辅助'比特'在一个特定的方向做一次两事件的概率测量(即测出两个事件发生的概率p_1,~p_2, p_1+p_2=1)就OK了。换句话说,在量子比特编码完成的情况下,只要一次量子测量操作加上一次计算量极小的经典计算就可得到结果。听上去很乐观?其实从算法到实验个人的感觉都不是这样,下面详细讲一讲。
================================================================
以下内容会包括一些我个人对这个成果的感受,由于刚涉足这个领域,也正在学习的过程之中,我的观点如果存在理解不到位的地方或者错误欢迎指出~
================================================================
经典向量到量子比特的编码过程是很困难的,如果有感兴趣的可以看附在后面比较详细的算法,此算法若直接应用于非归一化经典向量,当维度很高时经典计算部分的计算量很大,不比经典算法计算复杂度小。解决方案是,将信息直接按照此算法量子态系统的特点以一种新的方式取样,从而避免经典向量到量子态的转换这个过程。
以上是对算法本身的个人感觉。
接下来说说这个成果做的是什么。其实,它完成的,就是计算两个2维,4维,8维向量间的距离,并利用这个方法对一个小向量系统做了一个最简单分类,离目前很热门的机器学习所达到能力以及经典计算机还相差甚远,远到什么程度呢,我们来看看文章的原文数据表格下面的文字。
Experimental results for classifying four-dimensional vectors into two clusters. Reference vector A is (1, 0, 0, 0) and B is (0, 0, 1, 1). The data acquisition time is 2 minutes for each vector, collecting about 500 events.
简单翻译一下: 以 A(1, 0, 0, 0) 和 B(0, 0, 1, 1) 为分类标准,将一系列四维向量分类(即离A近则归类为A,离B近则归类为B),每个距离测量大约测了500个事例,每个向量花费时间约2分钟。
看到这,你对量子计算,更确切地说,光子计算的现状有了一个大致了解了吧。
为什么不能做到如理论文章所提及的算法那样呢?主要原因有两个:
一,对于辅助比特的编码: 如我前面所述,这个算法的实验依赖于如标签一样的辅助比特,而这个实验中是利用光子自旋来进行单辅助比特编码的,也就是,这个标签最多就能标记2个向量,所以实现不了向量簇情况的计算。这个问题的解决方法可能在于两个方面: 单光子多自由度编码已经开始发展,我们组去年关于这个的成果(两自由度光子的teleportation)发在了Nature上作为封面文章,这是一个很有飞跃性的进展,单光子编入三个量子比特是有可能实现的,这样一来辅助比特可以增加到能编入8个'标签';另外,我们需要设计出新的,多自由度甚至是多光子任意投影的测量方法,这是核心问题。
二,从光子实现来考虑,纠缠光子数目太难提升,具体原因有时间再补充。
量子计算学习算法是一个很有实践价值的算法,其算法十分简单并且操作简便,其测量只是对一个两事件概率的分析,从这个角度,它算法本身的实用价值远远超出了逆天的玻色采样(理论上可以求出矩阵的积和式,但矩阵维度增加是事件数指数增长,试想一下有10000面的硬币让你做抛硬币实验得到某一面朝上的概率是有多荒谬,所以玻色采样这个算法能做的只是证明一下量子计算机的优越性而已)。但即使这样,我们还有很长的路要走,这个实验成果做到的,只是对此算法最简单的情形做了一个演示,实现这个算法其困难之处上面已经分析过了。当上述两个问题以及最开始提到的量子比特编码方式的问题解决后,我们可以看看这个计算机能为我们提供多么恐怖的计算能力:
假设我们有n个量子比特位作为辅助比特,m个比特作为编码比特,则一簇向量的数目可以提高到 2^n个,每个向量的维度可以变成 2^m。当m=n=50时,我们便可以通过一次测量计算出一个1125899906842624维向量和一簇由1125899906842624个1125899906842624维向量构成的向量簇均值之间的距离!而当m, n继续增大时,这个计算机的计算速度迅速将成指数趋势增长,然而这一切都是脑洞大开的结果,目前我们还没有能够如此精确操纵量子态的能力。
尽管这个实验很简单,可能你感觉没有什么,但就是这么一个看上去简单的实验,完成它所要付出的努力也是非常多的,而且它的实现,起码给了我们一个希望,那就是:这个算法原理上是可以实现的,从更高的程度上说,它进一步证明了量子力学理论的成功。
=========下面是理论文章中求距离比较详细的描述供参考, 2015-7-10晚更新=========
考察普遍情况, 假设向量维度为 N=2^n , 复向量\vec{v}分量为 \{v_i=|v_i|e^{\mathrm{i}\phi}\} . 我们要完成如下任务: 将向量 \vec{u}\in R^N 放到V,W其中一个分类中, 两个分类各有m个参考示例, 记作\vec{v_j}\in V, ~\vec{w_k}\in W.一个通常的做法是比较\vec{u}与两类向量集合平均向量的距离, 即比较D_V=|\vec{u}-(1/M)\sum_j\vec{v_j}| 和 D_W=|\vec{u}-(1/M)\sum_k\vec{w_k}| 的大小. 如果 D_V 更小则将\vec{u} 放入集合 V 中, 反之则放入 W. 为了利用量子算法解决这个问题, 我们用 |u\rangle,~|v_j\rangle,~|w_k\rangle 表示归一化的矢量, 矢量的模|\vec{u}|,~|\vec{v_k}|,~|\vec{w_k}| , 作为独立参数, 即一个矢量表示为:
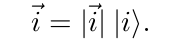
而归一化向量的编码采取如下方法, 以向量\vec{u}=(a,b,c,d)为例, 写成量子比特的直积形式:
\vec{u}=|\vec{u}|~(a'|0\rangle_1+b'|1\rangle_1)\otimes(c'|0\rangle_2+d'|1\rangle_2)
下脚标表示量子比特的编号. 其中, a'c'|\vec{u}|=a,~a'd'|\vec{u}|=b,~b'c'|\vec{u}|=c,~b'd'|\vec{u}|=d, 解这四个方程我们可以得到|i\rangle.
为了计算出距离, 以\vec{u} 与集合 V 为例, 构造态:
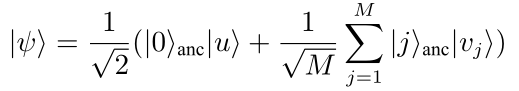

下脚标anc表示引入的辅助比特. 之后则对此量子态中的辅助比特在:
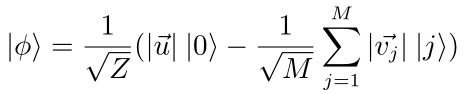

方向做一次测量, 其出现概率可表示为:
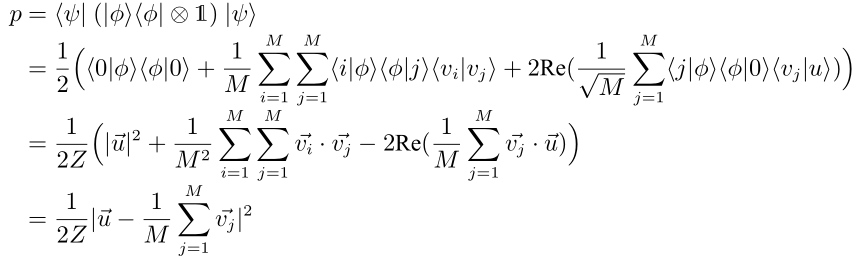

于是我们便得到了距离的表达式.
=============
2015-7-12更新=============
对于上面回答中的这一段, 这两天我又回想了一下那个实验过程, 做一些扩充.
一,对于辅助比特的编码: 如我前面所述,这个算法的实验依赖于如标签一样的辅助比特,而这个实验中是利用光子自旋来进行单辅助比特编码的,也就是,这个标签最多就能标记2个向量,所以实现不了向量簇情况的计算。这个问题的解决方法可能在于两个方面: 单光子多自由度编码已经开始发展,我们组去年关于这个的成果(两自由度光子的teleportation)发在了Nature上作为封面文章,这是一个很有飞跃性的进展,单光子编入三个量子比特是有可能实现的,这样一来辅助比特可以增加到能编入8个'标签';另外,我们需要设计出新的,多自由度甚至是多光子任意投影的测量方法,这是核心问题。
实际上这个文章是利用Sagnac-like的方法来实现比特编码的, 如下图:
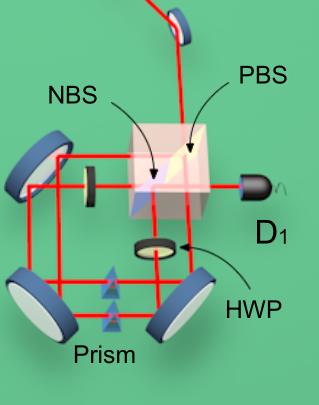
说白了, 就是给了两个编码路径, 每个路径对应一个所谓的'标签'. 如果采取这样的编码方式, 即使我们对单光子有足够好的测量和操纵能力, 除非我们有能力分离直积态中的单比特, 当比特数上升时所需要的实验资源数量也是成指数增加的, 然而分离直积态并且对直积态做编码又是一个有挑战性的事情.
参考文献
1. Lloyd S, Mohseni M, Rebentrost P. Quantum algorithms for supervised and unsupervised machine learning[J]. arXiv preprint arXiv:1307.0411, 2013.
2. Cai X D, Wu D, Su Z E, et al. Entanglement-Based Machine Learning on a Quantum Computer[J]. Physical review letters, 2015, 114(11): 110504.