可以用 Python 来干些什么有趣的事?

来强势回答一波:
在Kaggle上有一个特别有趣的比赛,叫“What's cooking?”
它是一个简单的机器学习的分类项目。在这个项目中,我们输入一系列的原料组合,算法会返回它所猜测的这些原料所属哪一个国家的菜系。
比如说,看到以下这些原料,你能想到它是怎样的菜系?原料: [姜黄, 蔬菜汤, 土豆, 玛萨拉, 馕, 扁豆, 红辣椒, 洋葱, 菠菜, 红薯] 是泰国菜,印度菜,还是墨西哥菜呢?答案是印度菜!
对于一个有经验的厨师,他对各国的菜式都有了解,那么这个问题并不难。他先前学习了上百种菜谱,洞悉各国家菜系的特征,因此当给出新的原料配料表时,他会根据了解的特征进行分析,并推断出这个配料属于哪个菜式——而机器学习也就是这么做的!具体而言,即我们的机器学习算法首先会对对给定的数据(也就是菜谱)进行学习,就像刚刚这位厨师一样,了解菜式的特征。当成功学习到这个知识之后,这个算法就能够学到相关的经验,进而对新给出的数据进行预测了!
那么在程序中我们是怎么实现的呢?具体步骤如下
- 使用Pandas的read_json()函数读取比赛所提供的训练集与测试集数据


pandas.read_json - pandas 0.23.4 documentation
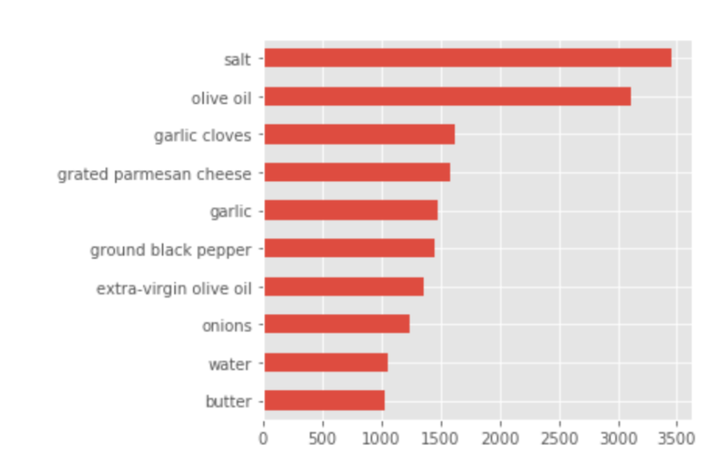
做了基本的统计,如计算意大利菜中最常见的10个原料

2. 数据预处理
- 数据清洗(如单复数、时态等变化)
由于菜品包含的佐料众多,同一种佐料也可能有单复数、时态等变化,为了去除这类差异,我们考虑将ingredients 进行过滤


- 使用TF-IDF提取特征
在该步骤中,我们将菜品的佐料转换成数值特征向量。考虑到绝大多数菜中都包含salt, water, sugar, butter等,采用one-hot的方法提取的向量将不能很好的对菜系作出区分。我们将考虑按照佐料出现的次数对佐料做一定的加权,即:佐料出现次数越多,佐料的区分性就越低。我们采用的特征为TF-IDF,相关介绍内容可以参考:链接


- 数据分割与重排:划分训练集/验证集/测试集
调用train_test_split()函数将训练集划分为新的训练集和验证集,便于之后的模型精度观测。
- 模型搭建
- 使用Sklearn调用Logistic Regression进行模型训练
- 最终得到0.79左右的验证集上得分
- 模型预测
- 预测之后,将结果提交到Kaggle,得分大致为:0.78580 左右
代码模板:
大家都看懂了咩,是不是很好玩~~