
利用500W条微博语料对评论进行情感分析

本文已在CSDN,CSDN微博 ,CSDN公众号 ,IT技术之家 等平台转发。
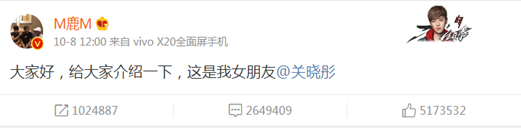
最近身边的人都在谈论一件事:10月8日中午的一条微博,引发了一场微博的轩然大波。导致微博瘫痪的原因是全球超人气偶像明星鹿晗发了一条“大家好,给大家介绍一下,这是我女朋友@关晓彤 ‘’。这条微博并@关晓彤。数据分析,可以在这里自取!
截止目前,鹿晗的这条微博已经被转发1024887,回复2649409,点赞5173532。

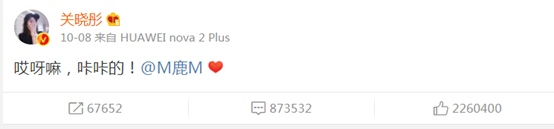
l 关晓彤的这条微博转发67652,回复873532,点赞:2260400。

这么庞大的数据量相当上亿的“肉鸡”(粉们和吃瓜群众)对微博的一次“攻击”。


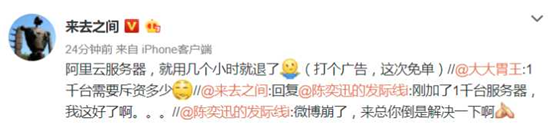
难怪微博工程师要一边结婚一边工作,都是鹿晗这条微博惹的祸。最后加了1000台服务器暂时顶住了。

这条微博评论非常的多了,大家对这件事态度怎么样?我们利用数据来分析一下。
原料:
1. 鹿晗微博3万条评论;
2. 关晓彤微博3万条评论;
3.500万微博语料,下载地址,密码:tvdo
工具:
1. Python3.6
2. SnowNLP(https://github.com/isnowfy/snownlp可方便的处理中文文本内容,是受到了TextBlob的启发而写的,由于现在大部分的自然语言处理库基本都是针对英文的,于是写了一个方便处理中文的类库,并且和TextBlob不同的是,这里没有用NLTK,所有的算法都是自己(不是本人)实现的,并且自带了一些训练好的字典。)
3. WordCloud,词云。
实施过程:
1.下载微博500万条记录,一定要到数据库所在机器上导入。
mysql - u root -p xxx <weibo500w.sql2.导入的时间会持续很长时间,导入完成后,为了提高效率可以进行去重和清理空的数据。
去重复内容:
delete from 表名 where id not in (select minid from (select min(id) as minid from 表名 group by 字段) b);
去值为NULL:
delete from 表名 where 字段名=NULL
去值为""空值
delete from 表名 where 字段名=''3.对微博语料进行情感分类,可以基于原有SnowNLP进行积极和消极情感分类和训练。
import re
from snownlp import sentiment
import numpy as np
import pymysql
from snownlp import SnowNLP
import matplotlib.pyplot as plt
from snownlp import sentiment
from snownlp.sentiment import Sentiment
conn = pymysql.connect(host='数据库IP', user='用户名', password='密码', charset="utf8",use_unicode=False) # 连接服务器
with conn:
cur = conn.cursor()
cur.execute("SELECT * FROM test.weibo WHERE weiboId < '%d'" % 6000000)
rows = cur.fetchall()
comment = []
for row in rows:
row = list(row)
comment.append(row[18])
def train_model(texts):
for li in texts:
comm = li.decode('utf-8')
text = re.sub(r'(?:回复)?(?://)?@[\w\u2E80-\u9FFF]+:?|\[\w+\]', ',',comm)
socre = SnowNLP(text)
if socre.sentiments > 0.8:
with open('pos.txt', mode='a', encoding='utf-8') as g:
g.writelines(comm +"\n")
elif socre.sentiments < 0.3:
with open('neg.txt', mode='a', encoding='utf-8') as f:
f.writelines(comm + "\n")
else:
pass
train_model(comment)
sentiment.train('neg.txt', 'pos.txt')
sentiment.save('sentiment.marshal')训练完成后会生成sentiment.marshal.3,将snownlp/sentiment/中sentiment.marshal.3直接替换,训练可以进行多轮训练,精度会更好。
4. 爬取两人的微博数据,使用http://m.weibo.com,解决懒加载问题,具体方式不在赘述,google 一下吧。
a. 微博提供了接口地址,微博提供API 地址,通过接口返回标准的json数据,自己想要存什么数据自己就存吧。
{
"comments": [
{
"created_at": "Wed Jun 01 00:50:25 +0800 2011",
"id": 12438492184,
"text": "love your work.......",
"source": "<a href="http://weibo.com" rel="nofollow">新浪微博</a>",
"mid": "202110601896455629",
"user": {
"id": 1404376560,
"screen_name": "zaku",
"name": "zaku",
"province": "11",
"city": "5",
"location": "北京 朝阳区",
"description": "人生五十年,乃如梦如幻;有生斯有死,壮士复何憾。",
"url": "http://blog.sina.com.cn/zaku",
"profile_image_url": "http://tp1.sinaimg.cn/1404376560/50/0/1",
"domain": "zaku",
"gender": "m",
"followers_count": 1204,
"friends_count": 447,
"statuses_count": 2908,
"favourites_count": 0,
"created_at": "Fri Aug 28 00:00:00 +0800 2009",
"following": false,
"allow_all_act_msg": false,
"remark": "",
"geo_enabled": true,
"verified": false,
"allow_all_comment": true,
"avatar_large": "http://tp1.sinaimg.cn/1404376560/180/0/1",
"verified_reason": "",
"follow_me": false,
"online_status": 0,
"bi_followers_count": 215
},
}
},
...
],
"previous_cursor": 0,
"next_cursor": 0,
"total_number": 7
}目前微博没有要求登录(可能是bug哦),建议sleep一下,否则很容易被微博大厂识别为爬虫行为二被封堵;b.数据存储,python很方便,直接存储在在文本中就好了,但是仍然需要对一些特殊表情,空,重复进行处理
import codecs
import re
import numpy as np
import pymysql
from snownlp import SnowNLP
import matplotlib.pyplot as plt
from snownlp import sentiment
from snownlp.sentiment import Sentiment
comment = []
with open('文件路径', mode='r', encoding='utf-8') as f:
rows = f.readlines()
for row in rows:
if row not in comment:
comment.append(row.strip('\n'))
def snowanalysis(self):
sentimentslist = []
for li in self:
#text = re.sub(r'(?:回复)?(?://)?@[\w\u2E80-\u9FFF]+:?|\[\w+\]', ',',li)
print(li)
s = SnowNLP(li)
print(s.sentiments)
sentimentslist.append(s.sentiments)
plt.hist(sentimentslist, bins=np.arange(0, 1, 0.01))
plt.show()
snowanalysis(comment)来看一执行过程:


读取每段评论并依次进行情感值分析,最后生成一个0-1之间的值,当值大于0.5时代表句子的情感极性偏向积极,当分值小于0.5时,情感极性偏向消极,当然越偏向两边,情绪越偏激。
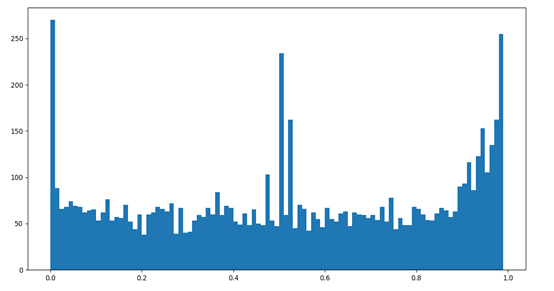

鹿晗微博评论情感分析,支持、祝福和反对、消极的的声音基本保持平衡。
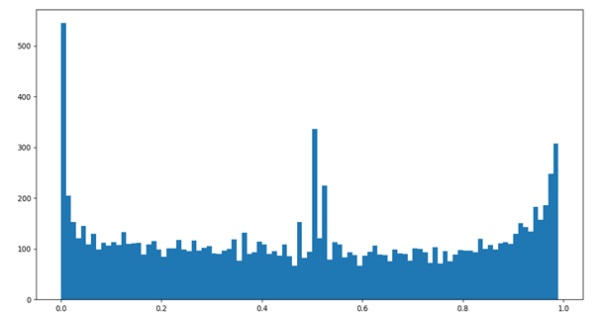

关晓彤微博微博评论情感分析,祝福、赞成的积极的情绪,分值大多高于0.5,而期盼分手或者表达消极情绪的分值,大多低于0.5。从图上来看已经是一边到的态势。(由于语料样本的数量,分析存在一定误差,感兴趣的同学一起完善情感样本库。)
b.我们一起看一次两人微博评论的词云,代码如下:
import pickle
from os import path
import jieba
import matplotlib.pyplot as plt
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
def make_worldcloud(file_path):
text_from_file_with_apath = open(file_path,'r',encoding='UTF-8').read()
wordlist_after_jieba = jieba.cut(text_from_file_with_apath, cut_all=False)
wl_space_split = " ".join(wordlist_after_jieba)
print(wl_space_split)
backgroud_Image = plt.imread('图片路径')
print('加载图片成功!')
'''设置词云样式'''
stopwords = STOPWORDS.copy()
stopwords.add("哈哈") #可以加多个屏蔽词
wc = WordCloud(
width=1024,
height=768,
background_color='white',# 设置背景颜色
mask=backgroud_Image,# 设置背景图片
font_path='E:\simsun.ttf', # 设置中文字体,若是有中文的话,这句代码必须添加,不然会出现方框,不出现汉字
max_words=600, # 设置最大现实的字数
stopwords=stopwords,# 设置停用词
max_font_size=400,# 设置字体最大值
random_state=50,# 设置有多少种随机生成状态,即有多少种配色方案
)
wc.generate_from_text(wl_space_split)#开始加载文本
img_colors = ImageColorGenerator(backgroud_Image)
wc.recolor(color_func=img_colors)#字体颜色为背景图片的颜色
plt.imshow(wc)# 显示词云图
plt.axis('off')# 是否显示x轴、y轴下标
plt.show()#显示
# 获得模块所在的路径的
d = path.dirname(__file__)
# os.path.join(): 将多个路径组合后返回
wc.to_file(path.join(d, "h11.jpg"))
print('生成词云成功!')
make_worldcloud('文本路径')

鹿晗评论词云,出现祝福、喜欢、支持等关键词,也出现分手等一些词。


关晓彤微博微博评论词云,出现很鹿晗,李易峰,不配,讨厌,不要脸的声音。
更多干货请浏览:
