怎么理解决策树、xgboost能处理缺失值?而有的模型(svm)对缺失值比较敏感呢?
16 个回答

首先从两个角度解释你的困惑:
- 工具包自动处理数据缺失不代表具体的算法可以处理缺失项
- 对于有缺失的数据:以决策树为原型的模型优于依赖距离度量的模型
回答中也会介绍树模型,如随机森林(Random Forest)和xgboost如何处理缺失值。文章最后总结了在有缺失值时选择模型的小建议。
1. 机器学习工具库开发的“哲学”
首先你有这个困惑是因为你直接调用了工具库,比如Python的sklearn和xgboost等,所以你认为算法A可以自动处理缺失值而B不可以。但真实情况是...开发者在封装工具库的时候就已经考虑到了使用者可能导入了含有缺失值的数据,所以加了一个缺失值处理的函数。处理缺失值的不是算法A,而是开发者额外写的函数。
但是,模型/算法本身不应该处理缺失值,处理缺失值的应该是用户。然而在现实情况下,如果用户不处理/不知道怎么处理,我们也必须提供一个默认的缺失值处理方法。但是这种自动处理的缺失值,效果往往不好,因为数据的精髓只有用户自己明白。
工具包提供自动数据清理的功能的好处:
- 防止用户导入的数据不符合模型要求而导致失败
- 节省用户的时间,提供一站式服务
工具包提供自动数据清理的功能的风险:
- 简单粗暴的处理模式会影响模型的结果,自动化的数据清理不可靠
- 用户应该提供符合模型要求的数据,这不是算法工具库的责任。算法工具包的默认要求就是用户提供适合的数据,因为用户对数据有更深刻的理解
- 可能会大幅度增加模型的运算时间
在软件工程领域,我们有一个比较经典的哲学思想叫做“让它出错”(let it fail)。指的是如果程序在运行中出现了错误,应该抛出异常(raise exception)而不是默默地装作没看到继续运行。放在机器学习工具包的场景下,如果发现数据有缺失,或者格式不对(比如不是数字型变量),应该报错而不是替用户处理。这也是为什么sklearn会报错,而不是替你处理。
恰好最我也开发过一些机器学习框架,相关的问题也想过很多。是否替使用者做了本该他自己做的事情,这需要在易用性和准确性中间找平衡。
2. 决策树模型怎么处理异常值?
看到这里,我希望你理解了为什么不是每个工具包都会自动处理缺失值。那我们分析一个具体个案 - 随机森林(Random Forests)。随机森林是已故统计学家Leo Breiman提出的,和gradient boosted tree一样,它的基模型是决策树。在介绍RF时,Breiman就提出两种解决缺失值的方法(Random forests - classification description):
- 方法1(快速简单但效果差):把数值型变量(numerical variables)中的缺失值用其所对应的类别中(class)的中位数(median)替换。把描述型变量(categorical variables)缺失的部分用所对应类别中出现最多的数值替代(most frequent non-missing value)。以数值型变量为例: X_{i,j} = Median(\forall X_{k,j}) \quad where \, k=1,2,3...n \; and \; X_{k,j} \,is\, present
- 方法2(耗时费力但效果好):虽然依然是使用中位数和出现次数最多的数来进行替换,方法2引入了权重。即对需要替换的数据先和其他数据做相似度测量(proximity measurement)也就是下面公式中的Weight( W ),在补全缺失点是相似的点的数据会有更高的权重W。以数值型变量为例: X_{k,j} =\frac{1}{n}\sum_{i=1,\ne k}^{n}W_{i,k} X_{i,j} \quad where \, k=1,2,3...n \; and \; X_{i,j} \,is\, present
注:公式仅做参考,未仔细检查。
Breiman说明了第二种方法的效果更好,但需要的时间更长。这也是为什么工具包中一般不提供数据补全的功能,因为会影响到工具包的效率。
3. xgboost怎么处理缺失值?
xgboost处理缺失值的方法和其他树模型不同。根据作者Tianqi Chen在论文[1]中章节3.4的介绍,xgboost把缺失值当做稀疏矩阵来对待,本身的在节点分裂时不考虑的缺失值的数值。缺失值数据会被分到左子树和右子树分别计算损失,选择较优的那一个。如果训练中没有数据缺失,预测时出现了数据缺失,那么默认被分类到右子树。具体的介绍可以参考[2,3]。


这样的处理方法固然巧妙,但也有风险:即我们假设了训练数据和预测数据的分布相同,比如缺失值的分布也相同,不过直觉上应该影响不是很大:)
4. 什么样的模型对缺失值更敏感?
主流的机器学习模型千千万,很难一概而论。但有一些经验法则(rule of thumb)供参考:
- 树模型对于缺失值的敏感度较低,大部分时候可以在数据有缺失时使用。
- 涉及到距离度量(distance measurement)时,如计算两个点之间的距离,缺失数据就变得比较重要。因为涉及到“距离”这个概念,那么缺失值处理不当就会导致效果很差,如K近邻算法(KNN)和支持向量机(SVM)。
- 线性模型的代价函数(loss function)往往涉及到距离(distance)的计算,计算预测值和真实值之间的差别,这容易导致对缺失值敏感。
- 神经网络的鲁棒性强,对于缺失数据不是非常敏感,但一般没有那么多数据可供使用。
- 贝叶斯模型对于缺失数据也比较稳定,数据量很小的时候首推贝叶斯模型。
总结来看,对于有缺失值的数据在经过缺失值处理后:
- 数据量很小,用朴素贝叶斯
- 数据量适中或者较大,用树模型,优先 xgboost
- 数据量较大,也可以用神经网络
- 避免使用距离度量相关的模型,如KNN和SVM
当然,这只是我的经验之谈,请谨慎参考。缺失值补全(missing value imputation)是一个非常大的方向,答案中只能简单带过,推荐深入了解。
5. 写在最后 - 如何优雅的调包?
不少答案中我都提到过“支持大家调包”,也就是调用现成的机器学习工具包。但“调包”最大的风险就是不知道自己用的到底是什么,常常一知半解。
这并不可怕,可怕的是当你感到迷惑的时候却没有追根溯源,搞清楚到底发生了什么。随着工具包的封装程度越来越高,调包的成本会越来越低。
但想要优雅的调包,最好还是知道包里装了些什么 ʕ•ᴥ•ʔ
[1] A Scalable Tree Boosting System
[2] What are the ways of treatng missing values in XGboost? · Issue #21 · dmlc/xgboost

sklearn包里的算法代入数据不能有缺失值,而xgboost可以。不是xgboost对缺失值不敏感,而是它对缺失值有默认的处理方法。
放一张stackoverflow的截图:xgboost: handling of missing values for split candidate search
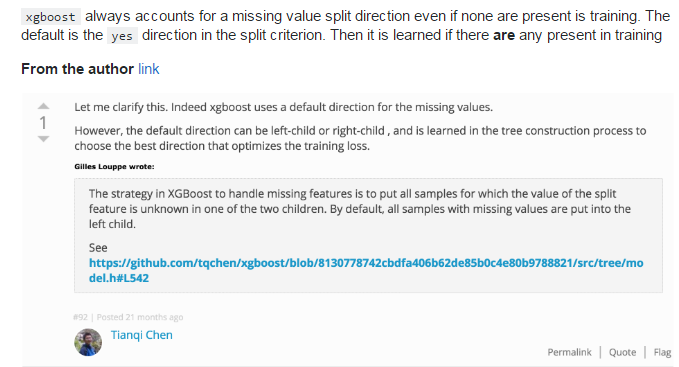

就是把缺失值分别放到左叶子节点和右叶子节点中,计算增益。哪个增益大就放到哪个叶子节点。