你用 Python 做过什么有趣的数据挖掘/分析项目?
69 个回答

(注:本文部分回答来源于
你是通过什么渠道获取一般人不知道的知识和信息的? - 何明科的回答以及
能利用爬虫技术做到哪些很酷很有趣很有用的事情? - 何明科的回答)从文中,大家也可以看到一个创业小团队艰辛的摸索过程。从一开始的一个想法,希望通过技术和科学改变世界,到碰巧能赚钱,到因为赚钱快而迷失了方向,到最后回归初心,做自己最喜欢的事情。
第零步:原点,大数据与价值
大概一年多以前,和几个小伙伴均认同一个趋势:觉得通过技术手段获取网上越来越丰富的数据,并基于这些数据做分析及可视化,必能产生有价值的结果,帮助大家改善生活。(大数据被叫烂了,所以用低调的方式来解释我们的初心)
第一步:开工,为基金服务
恰巧和几个基金的朋友(包括对冲基金和VC/PE基金)聊到这个趋势,他们非常认同这个观点并愿意付费,认为可以用这种实时且定量的方式来跟踪一些上市公司或者私有公司旗下的产品,来确定谁是有价值的投资目标。于是立马获得订单并促使我们开干,因为考虑到Python灵活及各类爬虫库的优势,最终选用Python来做数据获取的主体架构;也有新潮的小伙伴使用Go,同时用Go搭建了一个很酷的框架来制造分布式的智能爬虫,应对各种反爬策略。抓取数据主要来自于如下网站:
- 各应用商店:获取App的下载量及评论
- 大众点评及美团网:餐饮及各类线下门店消费及评价情况
- 汽车之家及易车:汽车的相关数据
- 58及搜房;房屋租售数据
- 新浪微博:用户的各种发言及舆论
- 财经数据:雪球及各类财经网站
- 宏观数据网站:天气、12306火车、机票网站
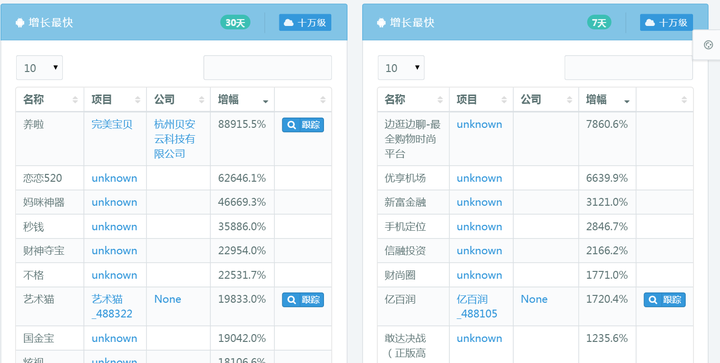
最初的产品纯粹是为基金服务。下图是在各个维度找出最有价值的App,各种量级范围内在30天/7天增长最快及评价最好榜单。(顺便吹一下牛,我们这个榜单很早就发现小红书App的快速增长趋势以及在年轻人中的极佳口碑)

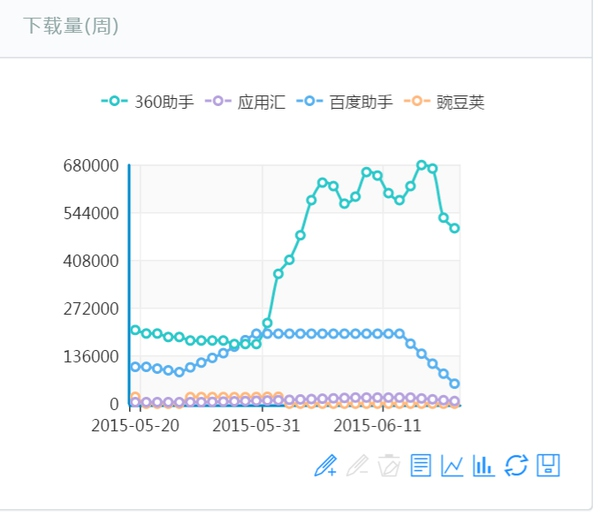
下图是对某个App的下载量跟踪,帮着基金做尽职调查。

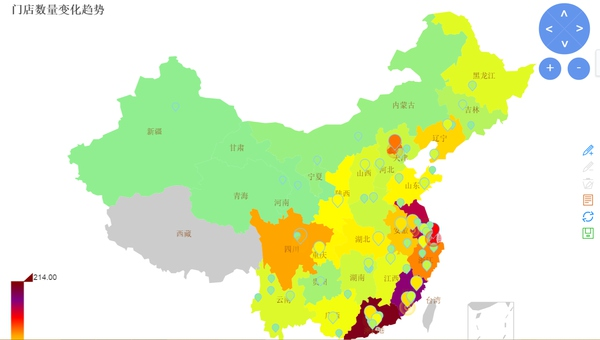
下图是某上市公司的门店变化情况,帮着基金跟踪TA的增长情况。

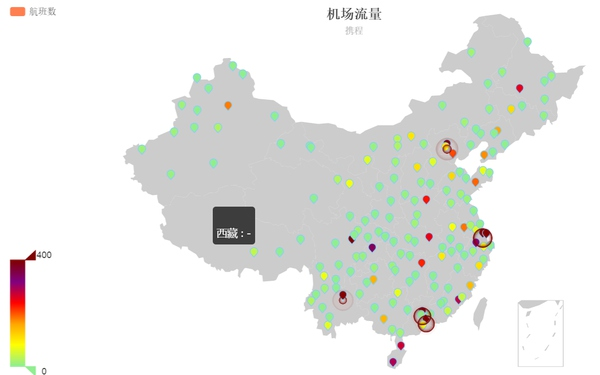
下图是国内各个机场的实时流量,帮着基金跟踪国内出行的实时情况,或许能从一个侧面反映经济是否正在走入下行通道。

第二步:扩展思路,开源和分享
为基金服务,虽然给钱爽快,但是也让方向越走越窄。首先,基金希望信息是独享的和封闭的,投资就是投资人之间的零和博弈,公开的信息就迅速会一钱不值,基金最在乎的就是信息的独享及提前量,所以各个基金都希望我们呈现的数据及分析结果能够独家。这样迅速让我们的方向收窄以及工作的趣味性降低,其次,毕竟对于基金而言,能分析的投资对象及方向是非常有限的。而且现阶段,大部分对冲基金里面的分析员的数据分析能力其实很弱:这些分析员里面能用VBA或者能在Excel里面使用矩阵及向量乘法的人几乎可以惊为天人;能写offset函数的人,就应该直接提拔了;大部分人停留在一个个数网页找数据的阶段。所以和他们起来十分费劲,除了提供一些粗暴的数据,并不能产生太有价值的结果。
在这段迷茫期,本来充满激情的数据分析工作,让大家味如爵蜡,感觉自己变成了一个外包公司。不过互联网大法好,做技术做互联网的核心思路是分享和开源,我们很快回归到这一点。并且这一点最终让我们做出了改变。有些分析虽然基金不买单,但是对一般的老百姓、对一般的媒体是有价值的,于是我们试着把这些数据分析及结果写出来,发布到知乎上供大家参考。
知乎是个好平台,坚持创作好内容迟早就会被发掘出来。很快一篇用数据分析黄焖鸡米饭为什么火遍全国的回答(
黄焖鸡米饭是怎么火起来的? - 何明科的回答)被知乎日报采用了。


这次被“宠幸”让团队兴奋不已,从而坚定了决心,彻底调整了整个思路,回到初心:不以解决基金关注的问题为核心,而以解决用户最关注的生活问题为核心。坚持以数据说话的套路,创作了许多点赞很多的文章并多次被知乎日报采用(
所答内容被「知乎日报」选用是什么感觉? - 何明科的回答),并专注在如下的领域:
- 汽车。比如:一年当中买车的最佳时间为何时? - 何明科的回答,什么样的车可以被称为神车? - 何明科的回答
- 餐饮。比如:为什么麦当劳和肯德基都开始注重现磨咖啡的推广,其优势与星巴克等传统咖啡行业相比在哪里? - 何明科的回答
- 消费品。比如:口罩(http://zhuanlan.zhihu.com/hemingke/20391296),尿不湿(http://zhuanlan.zhihu.com/hemingke/20385894)
- 招聘。比如:互联网人士年底怎么找工作(http://zhuanlan.zhihu.com/hemingke/20450600)
- 房地产,这个虐心的行业。比如:深圳的房地产走势(http://zhuanlan.zhihu.com/hemingke/20135185)
- 投融资。比如:用Python抓取投资条款的数据并做NLP以及数据分析:http://zhuanlan.zhihu.com/hemingke/20514731
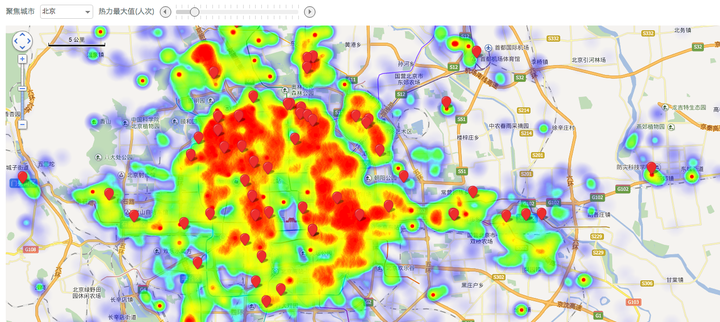
还共享了一些和屌丝青年生活最相关的分析及数据。下图是深圳市早晨高峰时段某类人群出行的热点图,通过热点分析,试图找出这类人群的居住和上班的聚集区。
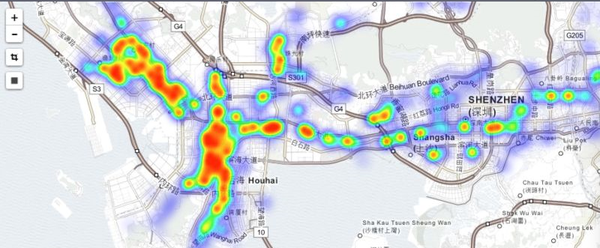

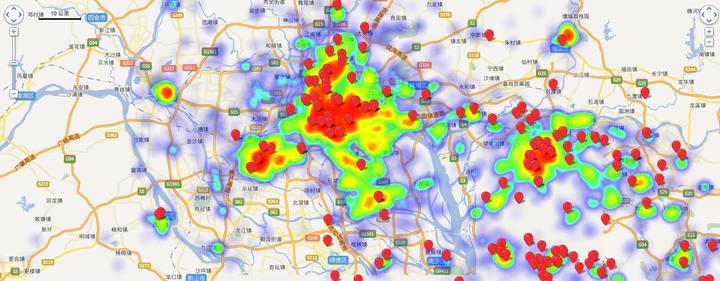
下图反映了在各时间段在深圳科技园附近下车的人群密度。


写这些报告,团队没有挣到一分钱,但是整个成就感和满意度大大上升。同时,在Python及各种技术上的积累也提高颇多,数据量级的积累也越发丰富,数据相关的各项技术也在不断加强。同时,顺势扩大了数据源:京东、淘宝等数据也纳入囊中。
第三步:扩展客户
在知乎上写这些报告,除了收获知名度,还收获意外之喜,一些知名品牌的消费品公司、汽车公司及互联网公司,主动找我们做一些数据抓取及分析。整个团队没有一个BD,也从来不请客户吃饭。
于是我们顺势做了如下的网站以及一个成熟的Dashboard框架(开发数据监控的Dashboard超有效率),目前主要监控和分析母婴、白酒、汽车及房地产四大行业,都是一些愿意花钱进行深度了解用户以及行业趋势的公司。收入自动上门,很开心!

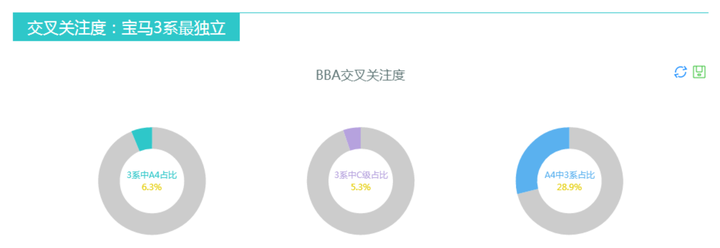
下图是抓取汽车之家的数据,做出BBA(奔驰宝马奥迪)这三大豪华品牌的交叉关注度,帮助品牌及4A公司了解他们用户的忠诚度以及品牌之间迁移的难度。

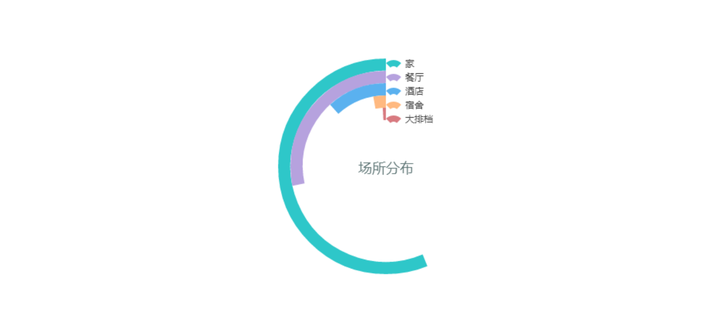
下图是抓取新浪微博的数据,分析广东白酒的消费场所

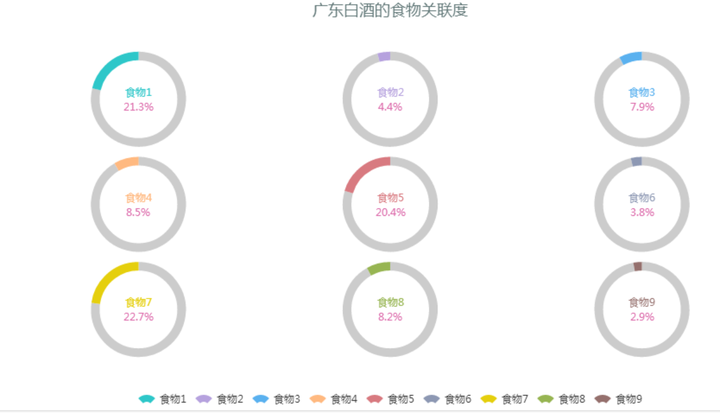
下图是抓取新浪微博的数据,分析广东白酒和各类食品的相关度。

除去为以上的品牌合作,我们数据风的文章也越来越受欢迎,曾经一周上了四次知乎日报(不知道
@周源@黄继新两位大大是否考虑给我们颁发个知乎日报大奖)。另外也有越来越多的知名媒体及出版社找到我们,虽然告知他们我们不写软文而只坚持按照数据结果来发表文章,他们依然表示欢迎。原来非五毛独立立场的数据风也能被媒体喜欢。自此,我们不断成为易车首页经常推荐的专栏。
第四步:尝试功能化平台化产品
降低与高大上基金的合作强度,转而与更接地气的各类品牌合作,让我们团队更贴近客户、更贴近真实需求。于是基于这些需求,我们开始尝试将之前在数据方面的积累给产品化,特别是能做出一些平台级的产品,于是我们开发出两款产品:
第一款:选址应用
选址是现在许多公司头疼的难题,以前完全是拍脑袋。因此我们开发出这样一套工具,帮助公司能够更理性更多维度得选址。
下图,我们抓取多个数据源并完成拼接,根据用户的快递地址,勾画出某时尚品牌用户的住址,帮助其选址在北京开门店。

下图,我们抓取多个数据源并完成拼接,根据大型超市及便利店与某类型餐馆在广州地区的重合情况,帮助某饮料品牌选定最应该进入的零售店面。

第二款:数据可视化
我们在工作中也深刻觉得以前制作图表和展示数据的方式太low、太繁琐,我们希望去改变这个现状,于是开发了一套基于Web来制作图表的工具
文图。远有Excel/Powerpoint对标,近有Tableau对标。
下图是文图丰富的案例库及模板库。

下图是简单的使用界面及丰富的图表类型。

下一步的工作:
- 与微信的整合,一键生成适合于微信传播的截图以及公众号格式文章,便于在社交媒体的传播
- 收集更多数据,目前已经覆盖40多家网站,涵盖衣食住行等多个方面
- 将数据SaaS化和开源,便于各类公司及用户使用。(咨询投行等Professional Service人士一定会懂的,你们每年不知道要重复多少遍更新各类宏观微观的经济和行业数据,现在只需要调用KPI)
最后,希望有一天它能部分替代已经在江湖上混迹二三十年的PowerPoint及Excel。
第五步:……
不可知的未来才是最有趣的。借用并篡改我们投资人的一句话:technology is fun, data is cool and science is sexy。初心未变,希望用数据用技术帮助更多的人生活得更美好。
—————————————————————————————————————
更多文章及分享请关注我的专栏,数据冰山:
http://zhuanlan.zhihu.com/hemingke

有两个建议吧。
- 完成《building machine learning systems with python》书上的所有projects,这本书除了封面其他里面的内容还是挺实用的。中文书名为 《机器学习系统设计》
- 完成kaggle playground和 101上的所有比赛,具体tutorial可以戳
- Getting Started With Python For Data Science https://www.kaggle.com/wiki/GettingStartedWithPythonForDataScience
- Getting Started With Python II Getting Started with Pandas: Kaggle's Titanic Competition https://www.kaggle.com/c/titanic-gettingStarted/details/getting-started-with-python-ii
- 另外补充一个用scikitlearn构建文本挖掘系统的教程,个人觉得写的很好,基本上做一遍大概的流程就很清晰了:scikit-learn文本挖掘系统学习(已完成)
另外可以看这篇blog:
大数据竞赛平台——Kaggle 入门---------------------------------
分割线补充:
我做过的比较好玩的应该是下载了豆瓣某一个爆照组的所有照片,然后结合发布者ID在其主页上找寻相关信息,然后按照地域进行统计算分布,然后在google map上画了出来... 不过这个就没什么含金量了,现在在水推荐系统。
ps:我也在入门中,欢迎一起探讨^_^