用 Python 写爬虫时应该注意哪些坑?



Web 抓取技术是一种可以让程序自动从网站抓取数据的技术。如果你对网络爬虫的常见设计模式、爬虫中遇到的坑以及相关技术原则等很感兴趣,本文正对你的胃口。下文会展示几个实例和一些典型问题,比如怎样才能不会被检测到,爬虫注意事项以及如何提高爬虫的速度等。

本文所有的示例都附有相应的 Python 代码片段,方便你直接参考学习。此外,也会介绍几个很有用的 Python 包。
使用实例
一般而言,我们想要抓取数据,是因为有各种各样的原因以及用途。比如下面这些:
- 抓取某个电商卖家的网页,了解你想买的东西的打折状况
- 爬取几个品牌商铺的网页数据,比较它们的价格
- 机票价格每天都会变动,这样我们可以爬取一个旅行网站的数据,每当有低价机票时自动提醒我们
教程
教程概览
- 适用的 Python 包
- 基础代码
- 坑(指在编写过程中你容易犯错的地方)
- 注意事项
- 加速——并行化
写在开始前:千万注意将爬虫技术用于正确的地方,绝对不能使用这个搞瘫别人的网站。

1 可用的包和工具
对于网站数据抓取来说并没有通用的解决方案,因为数据在网站上的存储方式往往是特定域该网站的情况。事实上,如果你想要爬取数据,你需要去弄懂目标网站的架构,然后自己构建一个爬取方案,或者使用可高度自定义的方案。
不过,你不需要重新造轮子:已经有许多 Python 包可以完成你的大部分工作。根据自己的编程水平和目标用途,你多多少少都能找到合适的包。
1.1 检查选项
大多数时候你都是在浏览网站的 HTML,通过浏览器的“检查”选项就可以做到这点。
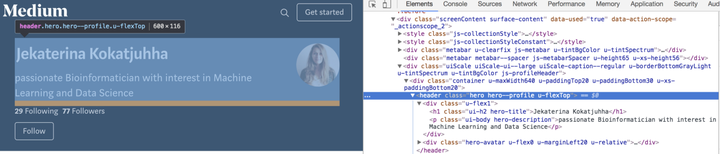

网站中保存了我的名字,我的头像和我的简介的这部分叫做 hero hero--profile u-flexTOP。保存了我的名字的 <1> 类称为 ui-h2 hero-title,简介这部分信息则保存在 <P> 类 ui-body hero-description 中。
1.2 Scrapy
有一个独立现成的数据爬取框架叫 Scrapy,除了能提取 HTML,它还提供了很多功能,例如导出格式数据以及日志等。Scrapy 同样可以高度自定义:能在不同的进程运行不同的“爬虫”,禁止使用 cookie(本地终端的数据)并设置下载延迟。它还可以使用 API 提取数据。但是,对于新手来说,使用 Scrapy 会稍微有些麻烦:你需要阅读教程和示例才能上手。
- 一些网站使用 cookie (用户终端的数据)来辨别机器人
- 网站可能会因为巨大的“爬虫”请求而超过负荷。
1.3 BeautifulSoup 和 Request 库
Beautiful soup 库能让你以一种优美的方式解析 HTML 源代码。使用它的时候,你还需要一个Request 库来获取 url 的内容。而且,你应该注意到方方面面,比如错误处理、如何导出数据、如何并行化爬虫等等。
我选择 BeautifulSoup 库因为它会让我自己亲自解决因为抓取产生的错误并且从这些错误里成长的越来越快。
2 基础代码
刚开始抓取网站非常简单。大多数情况下你都是在检查网站的 HTML 以获取你需要的类和 ID。假设我们接着有一个 html 结构,我们想爬取 main_price(主要价格)元素。注意:discounted_price(折扣价格)元素是可选的。
<body>
<div id="listings_prices">
<div class="item">
<li class="item_name">Watch</li>
<div class="main_price">Price: $66.68</div>
<div class="discounted_price">Discounted price: $46.68</div>
</div>
<div class="item">
<li class="item_name">Watch2</li>
<div class="main_price">Price: $56.68</div>
</div>
</div>
</body>基本的代码是导入所需的库,执行请求,解析 html,然后查找 class main_price。
在网站的另一个部分中,可能会出现 class main_price。为了避免从网页其他部分提取不必要的 class main_price,我们应该首先处理 id listings_prices,然后才能找到所有带 class main_price的元素。
from bs4 import BeautifulSoup
import requests
page_link ='https://www.website_to_crawl.com'
# fetch the content from url
page_response = requests.get(page_link, timeout=5)
# parse html
page_content = BeautifulSoup(page_response.content, "html.parser")
# extract all html elements where price is stored
prices = page_content.find_all(class_='main_price')
# prices has a form:
#[<div class="main_price">Price: $66.68</div>,
# <div class="main_price">Price: $56.68</div>]
# you can also access the main_price class by specifying the tag of the class
prices = page_content.find_all('div', attrs={'class':'main_price'})3 爬虫中的坑
3.1检查 robots 协议
网站爬取规定可以在 robot 爬取协议中找到。在网站主域名后面写上 robot.txt 就能看见,例如http://www.website_to_scrape.com/robots.txt。这些协议声明了网站的哪些部分禁止自动爬取或爬虫被允许爬取某个网页的次数。虽然我们都知道大多数人都不 care 这个,但还是建议尊重一点,哪怕你不打算遵守这些爬虫规定,至少也要看一遍,做到心中有数。
3.2 HTML 可能会“作恶”
HTML 标记可以包含 ID、类或两者皆有。HTML ID 会指定一个惟一的 ID,但 HTML 类却不是唯一的。类名或元素的更改都可能会破坏你的代码或传递错误的结果。
这里有两种方式可以避免这种情况或者至少提醒一下你:
- 使用特定的 ID 而不是 class,因为它不太可能被更改
- 确认元素值是否返回 None
price = page_content.find(id='listings_prices')
# check if the element with such id exists or not
if price is None:
# NOTIFY! LOG IT, COUNT IT
else:
# do something然而,由于某些字段是可选的(如我们在 HTML 示例中的 discounted_price),相应的元素不会出现在每个列表中。在这种情况下,你可以尝试计算这个特定元素返回 None 的次数占列表数量的百分比。如果是 100%,那你可能就需要检查元素名称是否已更改。
3.3 UA(用户代理)欺骗
每当你访问一个网站,它会通过 UA(用户代理)来获取你浏览器的信息。你在有些网站上看不到任何内容,除非你提供一个用户代理。另外,网站对不同的浏览器展示不同的内容。网站不希望屏蔽真正的用户,当如果你用同一个用户代理每秒发送两百个请求的话,你的行为看起来会非常的可疑。一种可能的解决方法是生成随机的用户代理或自己设置一个。
# library to generate user agent
from user_agent import generate_user_agent
# generate a user agent
headers = {'User-Agent': generate_user_agent(device_type="desktop", os=('mac', 'linux'))}
#headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux i686 on x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.63 Safari/537.36'}
page_response = requests.get(page_link, timeout=5, headers=headers)3.4 超时请求
默认情况下,Request 将无限期地一直等待响应。因此,建议设置超时参数。
# timeout is set to 5 secodns
page_response = requests.get(page_link, timeout=5, headers=headers)3.5 我被屏蔽了吗?
如果你发现频繁的出现状态代码像 404 未找到,403 被禁止,408 请求超时,这表明你可能被屏蔽了(自己心里要有数),这时就需要检查这些表示发生错误的状态代码并进行相应的处理。

同时,准备好处理请求中的异常。
try:
page_response = requests.get(page_link, timeout=5)
if page_response.status_code == 200:
# extract
else:
print(page_response.status_code)
# notify, try again
except requests.Timeout as e:
print("It is time to timeout")
print(str(e))
except # other exception3.6 IP 地址转换
即使你随机生成了你的用户代理,但你的所有请求还是从同一个 IP 地址中发出来的。这种情况并不反常因为图书馆,大学和企业往往只有几个 IP 地址。然而,如果有异常多的请求来自单个 IP 地址,服务器就可以检测到它。
proxies = {'http' : 'http://10.10.0.0:0000',
'https': 'http://120.10.0.0:0000'}
page_response = requests.get(page_link, proxies=proxies, timeout=5) 通过使用共享代理,你可以让网站看到代理服务器的 IP 地址,而不是你的。微屁恩可以将你连接到另一个网络当中,作为替代,微屁恩提供商的 IP 地址将被发送到网站。
3.7 蜜罐技术
蜜罐技术可以检测出爬虫。
有些“隐藏”链接用户无法看到,但爬虫却可以提取。这样的链接将会设置一个 CSS 样式来显示 None,它们可能有和背景色一样的颜色,或者甚至被移出页面的可见区域。一旦你的爬虫访问了这样的链接,你的 IP 地址就会被标记并且被进一步调查,甚至被立即屏蔽。
另一种发现爬虫的方法是添加一些目录树无限深的链接。然后,你需要做的就是限制检索页面的数量或限制遍历深度。
4 注意事项
当你在抓取之前,检查是否有可用的公用 API。使用公用 API 比 web 抓取相比会有更简单、更快(和更合法)的数据检索。比如这里提供了应用于不同目的的 Twitter API(https://developer.twitter.com/en/docs)。
如果你收集了大量数据,你可能需要考虑使用数据库来快速分析或检索数据。可以查看本教程学习如何使用 Python 创建本地数据库(http://zetcode.com/db/sqlitepythontutorial/)。
再次强调,不要每秒发送数百个请求,以防网站超过负荷。
5 加速——并行化
如果你决定并行化你的程序,请谨慎执行,以防服务器崩溃。
如果你从页面提取了大量信息并在抓取时对数据进行了预处理,那么你发送到页面的每秒请求数可能相对较低。
为了并行操作发送请求,你可能要使用一个多进程包。
假设我们有 100 个页面要处理,我们想给每个处理器分配相同数量的页面。如果 n 是 cpu 的数量,那么可以将所有页面平均分配到 n 个容器中,并将每个容器分配给一个处理器。每个进程都有自己的名称、目标函数模块和与之相关的参数。流程的名称可以重复使用,以便将数据写入特定的文件。
比如我们要抓取 4 千份房屋出租广告,如果我们有四个 CPU,可以为每个 CPU 分配 1K 页面,这样每秒产生四个请求,将抓取耗时缩短到了 17 分钟左右。
import numpy as np
import multiprocessing as multi
def chunks(n, page_list):
"""Splits the list into n chunks"""
return np.array_split(page_list,n)
cpus = multi.cpu_count()
workers = []
page_list = ['www.website.com/page1.html', 'www.website.com/page2.html'
'www.website.com/page3.html', 'www.website.com/page4.html']
page_bins = chunks(cpus, page_list)
for cpu in range(cpus):
sys.stdout.write("CPU " + str(cpu) + "\n")
# Process that will send corresponding list of pages
# to the function perform_extraction
worker = multi.Process(name=str(cpu),
target=perform_extraction,
args=(page_bins[cpu],))
worker.start()
workers.append(worker)
for worker in workers:
worker.join()
def perform_extraction(page_ranges):
"""Extracts data, does preprocessing, writes the data"""
# do requests and BeautifulSoup
# preprocess the data
file_name = multi.current_process().name+'.txt'
# write into current process file参考资料: https://hackernoon.com/web-scraping-tutorial-with-python-tips-and-tricks-db070e70e071