5月30日CTO俱乐部在北京举办的第99期主题活动的主讲嘉宾:洪强宁(豆瓣 首席架构师) 介绍豆瓣的技术架构和豆瓣自行开发的主要组件(如KV存储组件BeansDB,应用开发平台DAE,Python的Spark实现Dpark等)。 这个主题展示了豆瓣用十来人的团队完成的那些有价值的技术基础组件。
豆瓣,作为一家知名的互联网公司,不仅以其独特的文化氛围闻名,同样在技术架构和组件方面也有所创新和贡献。在CTO俱乐部北京举办的第99期主题活动中,豆瓣的首席架构师洪强宁介绍了豆瓣的技术架构和自主研发的几个主要组件。通过这次分享,我们可以深入了解到豆瓣的技术构成和背后的技术策略。
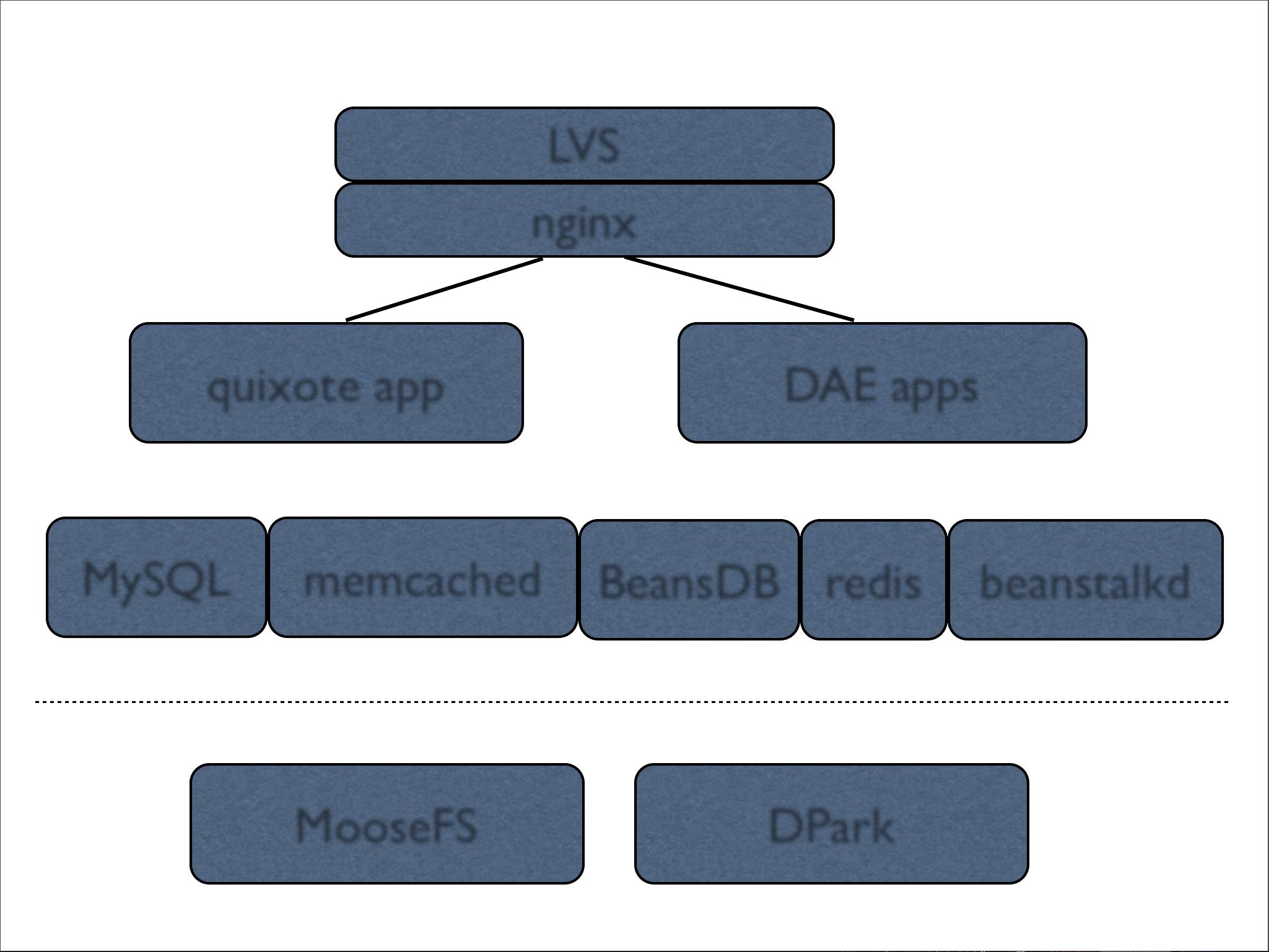
豆瓣的技术架构主要由多个组件和层级构成,其中包括了LVS、nginx、SCGI、HTTP、quixote、app、DAE、apps、MySQL、memcached、BeansDB、redis、beanstalk等。这些组件协同工作,共同支撑起豆瓣的高并发和大数据处理需求。
其中,DAE(Douban Application Engine)是豆瓣开发的一个自助式应用开发/部署环境,属于私有PaaS平台。DAE具有以下特点:
- 应用隔离的依赖管理,基于virtualenv和pip。
- 支持同步和异步worker,采用gevent,并支持websocket。
- 提供API来访问基础设施。
- 服务定义简便,基于thrift。
- 支持自动的水平扩展(scaleout)。
- 系统管理员(SA)负责整个资源池资源的管理。
- 应用开发者只需关注业务逻辑。
DAE的一些有趣特点包括:不使用虚拟机,而是通过Unix账号在进程级别管理;计划引入cgroups进行资源隔离;DAE自身的一些功能如部署和静态文件服务也是通过DAE应用实现的。DAE部署在7台物理机和1台虚拟机上,目前支持248个应用,并且每天处理约6千万请求。
BeansDB是豆瓣开发的键值存储服务,灵感来源于Dynamo,支持memcache协议。它在2008年启动项目,2009年开源,最初使用tokyocabinet作为存储引擎,后来在2010年改为bitcask存储格式。BeansDB的设计追求简单维护、稳定性能、易扩容、高可用性以及最终一致性。在豆瓣内部,BeansDB有两个集群,doubandb和doubanfs,分别用于存储小型数据(如文本信息)和中型数据(如图片、音频)。doubandb存储了约30亿条记录,9TB的数据,而doubanfs存储了约10亿条记录,150TB的数据。
DPark则是豆瓣基于UC Berkeley的Spark的Python实现,适合大规模数据的迭代计算,基于弹性分布式数据集(RDD)。它使用Apache Mesos进行资源管理,并在离线计算中替代了传统的Hadoop/Hive。DPark项目于2011年启动,2012年开源。
从洪强宁的介绍中我们不难看出,豆瓣在技术架构和组件方面的设计思路和实现手段。豆瓣的技术团队能够在有限的人力资源下,成功开发出一系列有价值的内部技术基础组件,这不仅体现了他们的技术实力,也为其他企业提供了技术实践的参考。特别是在开源精神的推动下,豆瓣愿意将这些技术组件如DAE和DPark贡献给开源社区,让更多开发者能够受益于这些技术成果。
















- 1
- 2
- 3
- 4
- 5
- 6
前往页