







目录
前言
CDC(Clock Domain Conversion)问题,一直是IC前端设计,FPGA设计的热点问题,特别是在校招面试笔试时候,是问的最多的一个问题,我之前关于这个问题以及相关问题,写了一些总结,但比较分散,今天简单汇总总结一下。
跨时钟域问题,又可以变向地细化地称为脉冲同步问题,脉冲检测问题等,看具体描述,大概是同一个意思:
例如,某光:
脉冲同步器的基本功能是从某个时钟域取出一个单时钟宽度脉冲,然后在新的时钟域中建立另一个单时钟宽度脉冲,请按照下面的模块接口信号设计一个脉冲检测器,并说明你设计的脉冲同步器的使用限制:
module sync_pulse( input in_rst_n, input in_clk, input in_pulse, input out_rst_n, input out_clk, output out_pulse ); //...... endmodule
本次总结的大致思路是这样的:

单比特信号的跨时钟域传输
慢时钟域到快时钟域
在慢时钟域内的一个脉冲信号,持续一个时钟周期,将其传输到快时钟域内:
这个问题,直接使用一个单比特同步器即可,因为快时钟一定能采样到慢时钟域内的信号,我们用两级寄存器进行同步的目的在于消除亚稳态问题,也就是说如果慢时钟域内的脉冲恰好在快时钟域的亚稳态窗口内,快时钟采样时刻(上升沿)采样得到的信号有可能出现亚稳态,再用触发器寄存一拍,可以大大降低最终输出出现亚稳态的概率。
最后如果也需要得到一个周期的脉冲,做一次时钟上升沿检测即可。
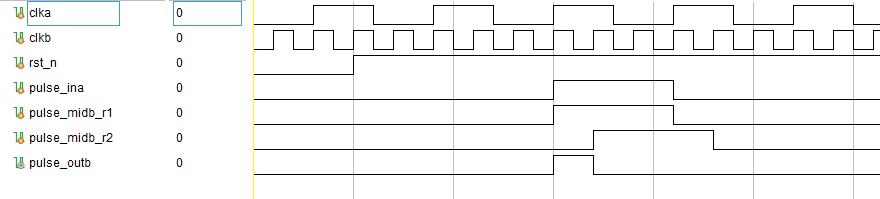
给出设计代码:
`timescale 1ns / 1ps
//
// Company:
// Engineer: https://blog.csdn.net/Reborn_Lee
// Create Date: 2019/09/24 15:22:59
// Module Name: slow2fast_cdc
// Project Name:
// Target Devices:
// Tool Versions:
//
module slow2fast_cdc(
input clka,
input clkb,
input rst_n,
input pulse_ina,
output pulse_outb
);
reg pulse_midb_r1, pulse_midb_r2;
always@(posedge clkb or negedge rst_n) begin
if(~rst_n) begin
pulse_midb_r1 <= 0;
pulse_midb_r2 <= 0;
end
else begin
pulse_midb_r1 <= pulse_ina;
pulse_midb_r2 <= pulse_midb_r1;
end
end
assign pulse_outb = ~pulse_midb_r2 & pulse_midb_r1;
endmodule
testbench文件:
`timescale 1ns / 1ps
//
// Company:
// Engineer: https://blog.csdn.net/Reborn_Lee
// Create Date: 2019/09/24 15:26:38
// Design Name:
// Module Name: sim_s2f_cdc
//
module sim_s2f_cdc(
);
reg clka, clkb;
reg rst_n;
reg pulse_ina;
wire pulse_outb;
initial begin
clka = 0;
forever
#6 clka = ~ clka;
end
initial begin
clkb = 0;
forever
#2 clkb = ~ clkb;
end
initial begin
rst_n = 0;
pulse_ina = 0;
#10
rst_n = 1;
#10
@(posedge clka)
pulse_ina = 1;
@(posedge clka)
pulse_ina = 0;
end
slow2fast_cdc inst_slow2fast(
.clka(clka),
.clkb(clkb),
.rst_n(rst_n),
.pulse_ina(pulse_ina),
.pulse_outb(pulse_outb)
);
endmodule
快时钟域到慢时钟域
从快时钟域clka到慢时钟域clkb,如果快时钟域内的一个脉冲信号持续一个时钟周期,如何同步到慢时钟域内呢?
这里存在一个问题是快时钟采样不到慢时钟域内输入脉冲的一个情况,对于这种问题,我们的通用方法为:
简单说来,就是在快时钟域内先进行脉冲展宽,展宽到快时钟内能采样到为止;展宽之后的信号在快时钟域clkb下用两级寄存器同步下就好了,再用上升沿检测检测到同步后的信号得到一个时钟clkb周期的脉冲,表示同步完成。
这里有一个问题就是脉冲展宽,展宽到什么地步?
我们先入为主,看看下图:
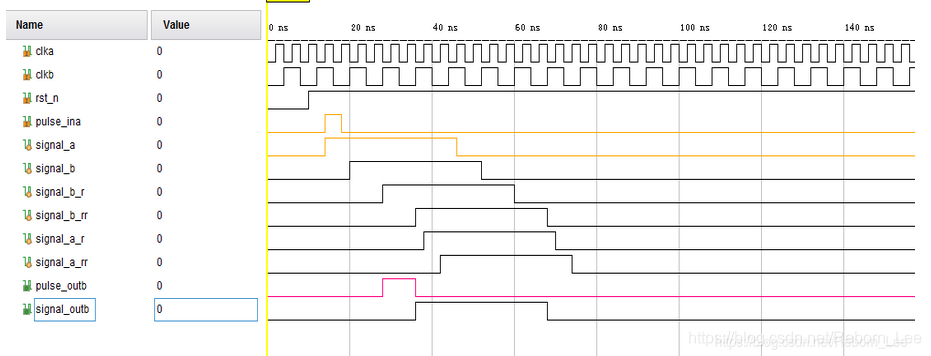
在clka内,检测到pulse_ina为高的时候,对展宽信号signal_a拉高,什么时候拉低呢?也就是对展宽信号拉低?
需要一个反馈信号,反馈信号有效的时候,拉低展宽信号。反馈信号是什么呢?
看上图,对signal_b_rr,同步到时钟域a,最终得到的这个信号signal_a_rr作为反馈信号,已经展宽的足够宽,宽到慢时钟能够采样到。
给出设计代码:
module Sync_Pulse(
input clka,
input clkb,
input rst_n,
input pulse_ina,
output pulse_outb,
output signal_outb
);
//-------------------------------------------------------
reg signal_a;
reg signal_b;
reg signal_b_r;
reg signal_b_rr;
reg signal_a_r;
reg signal_a_rr;
//-------------------------------------------------------
//在clka下,生成展宽信号signal_a
always @(posedge clka or negedge rst_n)begin
if(rst_n == 1'b0)begin
signal_a <= 1'b0;
end
else if(pulse_ina == 1'b1)begin
signal_a <= 1'b1;
end
else if(signal_a_rr == 1'b1)
signal_a <= 1'b0;
else
signal_a <= signal_a;
end
//-------------------------------------------------------
//在clkb下同步signal_a
always @(posedge clkb or negedge rst_n)begin
if(rst_n == 1'b0)begin
signal_b <= 1'b0;
end
else begin
signal_b <= signal_a;
end
end
//-------------------------------------------------------
//在clkb下生成脉冲信号和输出信号
always @(posedge clkb or negedge rst_n)begin
if(rst_n == 1'b0)begin
signal_b_r <= 'b0;
signal_b_rr <= 'b0;
end
else begin
signal_b_rr <= signal_b_r;
signal_b_r <= signal_b;
end
end
assign pulse_outb = ~signal_b_rr & signal_b_r;
assign signal_outb = signal_b_rr;
//-------------------------------------------------------
//在clka下采集signal_b_rr,生成signal_a_rr用于反馈拉低signal_a
always @(posedge clka or negedge rst_n)begin
if(rst_n == 1'b0)begin
signal_a_r <= 'b0;
signal_a_rr <= 'b0;
end
else begin
signal_a_rr <= signal_a_r;
signal_a_r <= signal_b_rr;
end
end
endmodule仿真文件同单比特同步器;
仿真波形为:
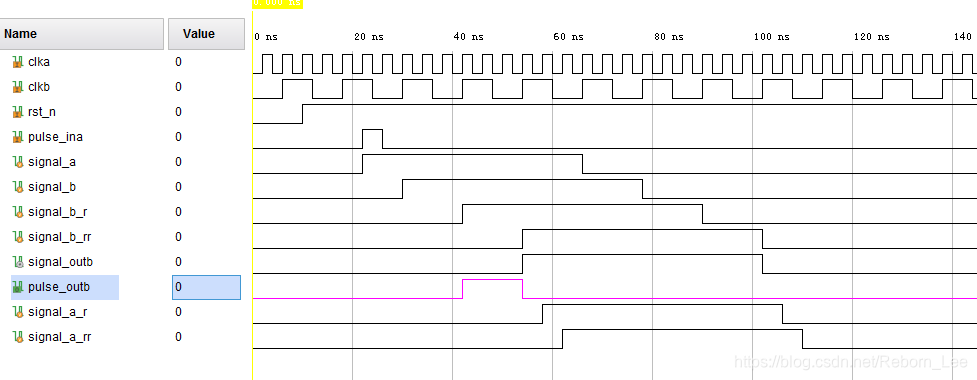
多比特信号的跨时钟域传输
异步FIFO
无论是从快到慢,还是从慢到快,都可以用异步FIFO来处理:
学习异步FIFO要善于与同步FIFO做一个对比,同步FIFO见链接:
对于同步FIFO的设计,很容易通过一个计数器来判断空满,由于读写FIFO都在同一个时钟域,所以可以使用如下思路:
写一个数据,计数器加1;读一个数据,计数器减1;如此,当计数器为0,代表写了多少个数据就读了多少个数据,FIFO为空;
假设FIFO的深度为N,则计数到N,表示FIFO满;
如下图可以清晰示意:
可见,写指针总是指向下一个要写入的RAM空间,而读指针总是指向当前要读取的数据空间。
当FIFO复位时,读写指针指向0地址处,之后每写一个数据,写指针移动到下一个地址处,读一个数据,读指针也移动到下一个地址处。正常的状态应该是读指针一直在追写指针,这样的话就不会发生读空的情况;
但也存在这种情况,写指针反过来追上了读指针,这下可好了,二者又相等了,这时候不是空,反而是满,这时,就不能继续写了,否则就会出现写数据覆盖原来数据的情况,称之为溢出。
上面也说了,对于同步FIFO来说,我们可以设置一个计数器,写一个数据,计数器加1,读一个数据,计数器减1,如果计数器为0,则表示为空,如果计数器为N(N为FIFO深度)则为满。
对于异步FIFO呢?
如何判断空满呢?能否仿效同步FIFO,也设置一个计数器呢?
答案是不能,因为异步FIFO的读写指针位于不同的时钟域,如果设置一个计数器,请问这个计数器是在读时钟域内计数呢?还是在写时钟域内计数呢?
我们只能通过判断读写指针的关系进行判断FIFO是空还是满?可是如上图所示,读写指针相等有可能为空,也可能为满?我们必须想出一个办法,解决这种判断模糊的问题。
我们的方法是对于读写指针多加一位指示位。原理如下:
同样,在写时钟域内,如果写一个数据,写指针加1,即移动到下一个地址处;
在读时钟域内,如果读一个数据,则读指针加1,即移动到下一个地址处;
当读写指针的最高位(MSB)(most significant bit)相等,且剩余其他位也相等时,表示FIFO为空;
当读写指针的最高位(MSB)不等,但是剩余其他位相等时,表示FIFO为满。
具体过程如下:
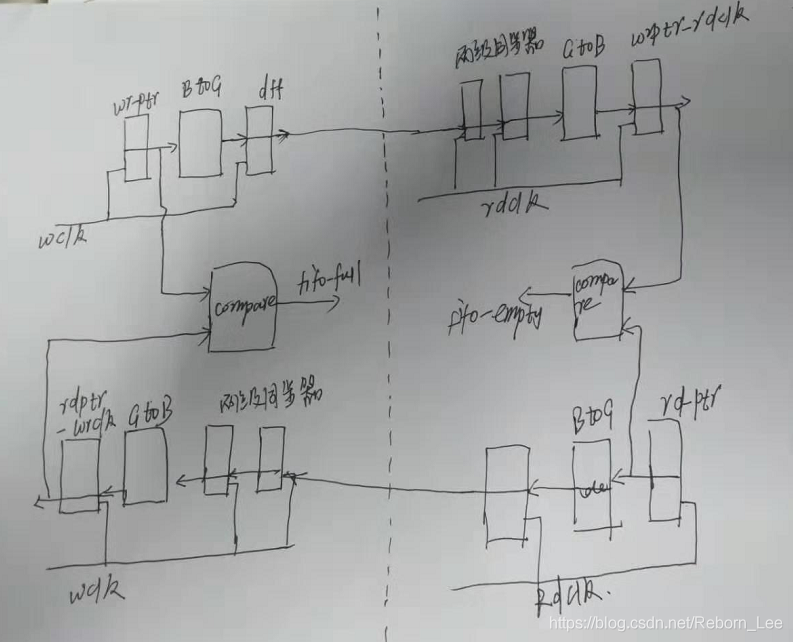
注意,上面去判断读写指针时,是需要同步到同一个时钟域内的,例如需要判断FIFO是否为满,需要将读指针同步到写时钟域内,如何进行同步呢?
过程是:
首先,当读一个数据,读指针加1,这里用的还是二进制编码,之后对这个读指针变换为格雷码,寄存一拍,然后用写时钟两级同步,在将同步过来的信号转换为二进制编码,寄存一拍与写指针比较。
判断是否为空时,需要将写指针同步到读时钟域,方式同上。
下面的话可以不用看了(需要升级理解的可以看看):
从上述过程中,在判断是否为满时,我们可以看到,将写指针同步到读时钟域需要几个周期的时间,同步过去后,与写指针进行比较,由于在这段时间内,读数据有可能也正在继续,所以,有可能存在着还保留着几个未写满的空间,也就是可用于写入的位置比实际的要多出几个。这是异步FIFO操作保守的一面,这样做才不会引起上溢,即写数据覆盖原来的数据。
同样,在判断是否为空时,需要将写指针同步到读时钟域,需要花费几个周期的时间,同步过去后,与读指针对比,由于这段时间内,写数据有可能也在继续,所以二者相等时,有可能还有几个数据没有读完,也就是还有几个数据可用。这也是异步FIFO保守的一面,这样不会出现下溢的情况,也即读空了继续读的情况。
根据上面的原理,设计一个异步FIFO:
主程序:
module asyfifo#(
parameter DATA_WIDTH = 8,
ADDR_WIDTH = 4,
FIFO_DEPTH = (1<<ADDR_WIDTH)
)(
input rst_n,
//write ports
input wrclk,
input wren,
input data_in,
output wr_full,
//read ports
input rdclk,
input rden,
output data_out,
output rd_empty
);
//write pointer control logic
//write pointer with wraparound and no wraparound
reg [ADDR_WIDTH : 0] wr_ptr_wrap, wr_ptr_wrap_nxt;
wire [ADDR_WIDTH - 1 : 0] wr_ptr;
//write pointer with wraparound state change
always@(posedge wrclk or negedge rst_n)begin
if(~rst_n) wr_ptr_wrap <= 0;
else wr_ptr_wrap <= wr_ptr_wrap_nxt;
end
always@(*) begin
wr_ptr_wrap_nxt = wr_ptr_wrap;
if(wren) wr_ptr_wrap_nxt = wr_ptr_wrap_nxt + 1;
else ;
end
//convert the binary write pointer to gray, flop it, and then pass it to read domain
reg [ADDR_WIDTH : 0] wr_ptr_wrap_gray;
wire [ADDR_WIDTH : 0] wr_ptr_wrap_gray_nxt;
//instantiate the module binary to gray
binary_to_gray #(.WIDTH(ADDR_WIDTH)) inst_binary_to_gray_wr(
.binary_value(wr_ptr_wrap_nxt),
.gray_value(wr_ptr_wrap_gray_nxt)
);
always@(posedge wrclk or negedge rst_n) begin
if(~rst_n) wr_ptr_wrap_gray <= 0;
else wr_ptr_wrap_gray <= wr_ptr_wrap_gray_nxt;
end
//synchronize wr_ptr_wrap_gray into read clock domain
reg [ADDR_WIDTH:0] wr_ptr_wrap_gray_r1, wr_ptr_wrap_gray_r2;
always@(posedge rdclk or negedge rst_n) begin
if(~rst_n) begin
wr_ptr_wrap_gray_r1 <= 0;
wr_ptr_wrap_gray_r2 <= 0;
end
else begin
wr_ptr_wrap_gray_r1 <= wr_ptr_wrap_gray;
wr_ptr_wrap_gray_r2 <= wr_ptr_wrap_gray_r1;
end
end
//convert wr_ptr_wrap_gray_r2 back to binary form
reg [ADDR_WIDTH : 0] wr_ptr_wrap_rdclk;
wire [ADDR_WIDTH : 0] wr_ptr_wrap_rdclk_nxt;
gray_to_binary #(.WIDTH(ADDR_WIDTH)) inst_gray_to_binary_wr(
.gray_value(wr_ptr_wrap_gray_r2),
.binary_value(wr_ptr_wrap_rdclk_nxt)
);
always@(posedge rdclk or negedge rst_n) begin
if(~rst_n) wr_ptr_wrap_rdclk <= 0;
else wr_ptr_wrap_rdclk <= wr_ptr_wrap_rdclk_nxt;
end
assign wr_ptr = wr_ptr_wrap[ADDR_WIDTH - 1 : 0];
//read pointer control logic
//read pointer with wraparound and no wraparound
reg [ADDR_WIDTH : 0] rd_ptr_wrap, rd_ptr_wrap_nxt;
wire [ADDR_WIDTH - 1 : 0] rd_ptr;
//read pointer with wraparound state change
always@(posedge rdclk or negedge rst_n) begin
if(~rst_n) rd_ptr_wrap <= 0;
else rd_ptr_wrap <= rd_ptr_wrap_nxt;
end
always@(*) begin
rd_ptr_wrap_nxt = rd_ptr_wrap;
if(rden) rd_ptr_wrap_nxt = rd_ptr_wrap_nxt + 1;
else ;
end
//convert binary read pointer to gray
reg [ADDR_WIDTH : 0] rd_ptr_wrap_gray;
wire [ADDR_WIDTH : 0] rd_ptr_wrap_gray_nxt;
binary_to_gray #(.WIDTH(ADDR_WIDTH)) inst_binary_to_gray_rd(
.binary_value(rd_ptr_wrap_nxt),
.gray_value(rd_ptr_wrap_gray_nxt)
);
always@(posedge rdclk or negedge rst_n) begin
if(~rst_n) rd_ptr_wrap_gray <= 0;
else rd_ptr_wrap_gray <= rd_ptr_wrap_gray_nxt;
end
//synchronize rd_ptr_wrap_gray into write clock domain
reg [ADDR_WIDTH : 0] rd_ptr_wrap_gray_r1, rd_ptr_wrap_gray_r2;
always@(posedge wrclk or negedge rst_n) begin
if(~rst_n) begin
rd_ptr_wrap_gray_r1 <= 0;
rd_ptr_wrap_gray_r2 <= 0;
end
else begin
rd_ptr_wrap_gray_r1 <= rd_ptr_wrap_gray;
rd_ptr_wrap_gray_r2 <= rd_ptr_wrap_gray_r1;
end
end
//convert rd_ptr_wrap_gray_r2 into binary form
reg [ADDR_WIDTH : 0] rd_ptr_wrap_wrclk;
wire [ADDR_WIDTH : 0] rd_ptr_wrap_wrclk_nxt;
gray_to_binary #(.WIDTH(ADDR_WIDTH)) inst_gray_to_binary_rd(
.gray_value(rd_ptr_wrap_gray_r2),
.binary_value(rd_ptr_wrap_wrclk_nxt)
);
always@(posedge wrclk or negedge rst_n) begin
if(~rst_n) rd_ptr_wrap_wrclk <= 0;
else rd_ptr_wrap_wrclk <= rd_ptr_wrap_wrclk_nxt;
end
assign rd_ptr = rd_ptr_wrap[ADDR_WIDTH - 1 : 0];
wire wr_full_nxt;
reg wr_full;
assign wr_full_nxt = (wr_ptr_wrap_nxt[ADDR_WIDTH] != rd_ptr_wrap_wrclk_nxt[ADDR_WIDTH]) && (wr_ptr_wrap_nxt[ADDR_WIDTH - 1: 0]
== rd_ptr_wrap_wrclk_nxt[ADDR_WIDTH - 1 : 0]);
always@(posedge wrclk or negedge rst_n) begin
if(~rst_n) wr_full <= 0;
else wr_full <= wr_full_nxt;
end
wire rd_empty_nxt;
reg rd_empty;
assign rd_empty_nxt = (rd_ptr_wrap_nxt[ADDR_WIDTH] == wr_ptr_wrap_rdclk_nxt[ADDR_WIDTH])&&(rd_ptr_wrap_nxt[ADDR_WIDTH - 1:0]
== wr_ptr_wrap_rdclk_nxt[ADDR_WIDTH - 1 : 0] );
always@(posedge rdclk or negedge rst_n) begin
if(~rst_n) rd_empty <= 0;
else rd_empty <= rd_empty_nxt;
end
sram #(.ADDR_WIDTH(ADDR_WIDTH),
.DATA_WIDTH(DATA_WIDTH)
) inst_sram(
.wren(wren),
.wraddr(wr_ptr),
.wrdata(data_in),
.rden(rden),
.rdaddr(rd_ptr),
.rddata(data_out)
);
endmodule二进制转格雷码:
module binary_to_gray#( parameter WIDTH = 4 )(
input [WIDTH:0] binary_value,
output [WIDTH:0] gray_value
);
assign gray_value = (binary_value >> 1) ^ binary_value;
endmodule格雷码转二进制:
module gray_to_binary #( parameter WIDTH = 4)(
input [WIDTH : 0] gray_value,
output [WIDTH : 0] binary_value
);
assign binary_value[WIDTH] = gray_value[WIDTH];
genvar i;
generate
for(i = 0; i <WIDTH - 1; i = i + 1) begin
binary_value[i] = gray_value[i] ^ binary_value[i + 1];
end
endgenerate
endmodule双端口SRAM:
module sram #(
parameter ADDR_WIDTH = 4,
DATA_WIDTH = 8
)(
input wren,
input wrdata,
input wraddr,
input rden,
input rdaddr,
output rddata
);
localparam RAM_DEPTH = (1<< ADDR_WIDTH);
reg [DATA_WIDTH - 1 : 0] mem[RAM_DEPTH - 1 : 0];
// synopsys_translate_off
integer i;
initial begin
for(i=0; i < RAM_DEPTH; i = i + 1) begin
mem[i] = 8'h00;
end
end
// synopsys_translate_on
always@(*) begin
if(wren) mem[wraddr] = wrdata;
else ;
end
always@(*) begin
if(rden) rddata = mem[rdaddr];
else ;
end
endmodule注意:上述代码,只作为参考,暂时并未仿真验证;
握手协议
这种方法,额,,,没用过。直接给出之前的链接吧。
https://blog.csdn.net/Reborn_Lee/article/details/89647526
暂时写到这里,以后需要更正在更新。
















 716
716











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











